

各種產業領域的實時企業AI應用程式需要實時可操作的數據和具有與雲無關互連的ML洞察平臺。 Verizon Media的Edge AI是一種專門構建的平臺,致力於幫助客戶在數據管理和機器學習操作(MLOP)的交叉點上工作,從而使他們可以在全球範圍內的異構基礎架構上工作。 將人工智慧移至網路邊緣,讓決策與行動近乎即時。 這在工業和消費細分市場中打開了一系列令人興奮和變革性的應用,我們在本系列的第一篇部落格文章中概述了這些應用。
正如我們將解釋的,在許多方面,邊緣AI的目的是連接在邊緣設計,開發和部署商業AI應用程式所需的所有元素,以實現實時企業使用案例。 這包括我們的內容交付網路(CDN)(幾乎全球每個網際網路用戶的延遲僅為10-25毫秒),我們的內部部署5G技術,可擴展的應用程式平臺即服務(aPaaS)層,雲數據管理,全面的安全性以及深入的監控和分析。
從Edge AI開發流程一開始,我們的願景就是創建一個與基礎設施無關的輕量容器化平臺,與雲無關的互連,從而在邊緣提供實時,可行的數據和機器學習見解。 此願景反過來幫助我們堅持平臺的目標和技術決策,如下圖所示。
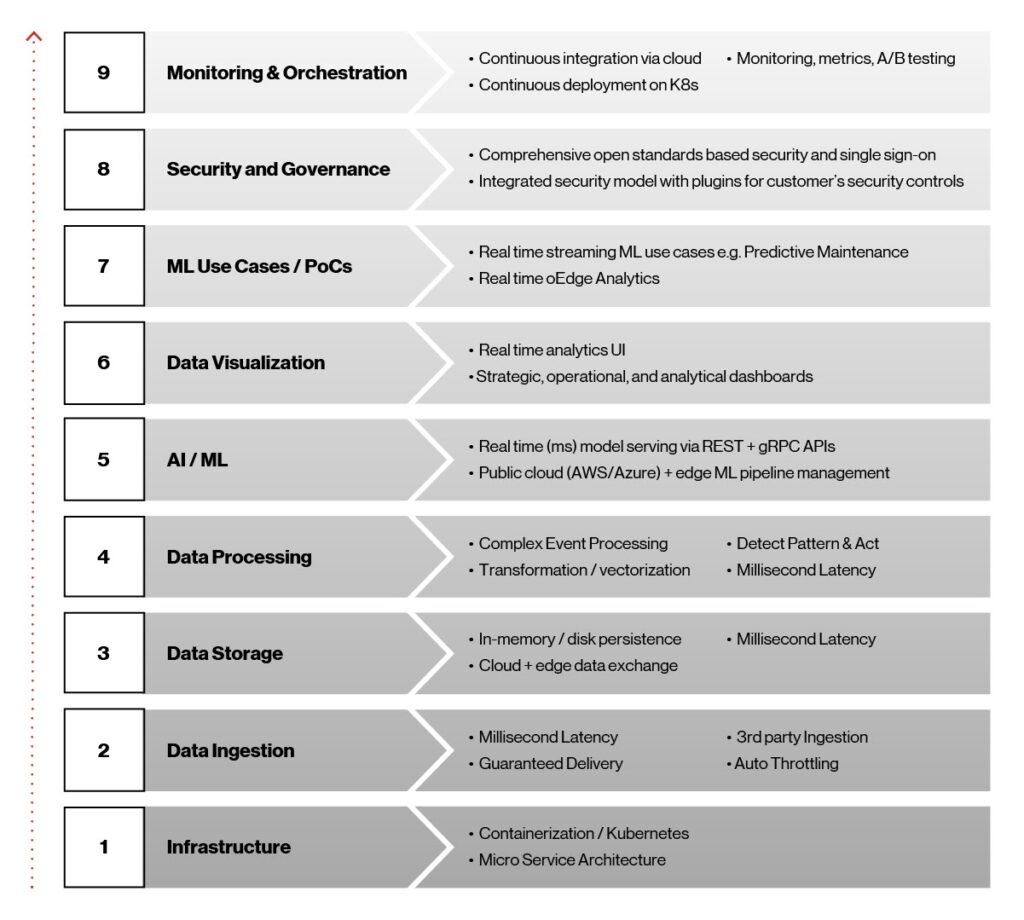
圖1. Edge AI架構元素。
這九個要素在使Edge AI平臺成為可能方面起著重要作用,並且在商業解決方案部署到生產中時對其成功至關重要。 讓我們從下到上仔細看一下這些元素。
-
Infrastructure:Kubernetes和容器是實現高可用性,超低延遲和將AI/ML模型快速部署到邊緣的明顯選擇。 與基礎設施無關的Kubernetes是一個可移植,可擴展的開放原始碼平臺,用於管理容器化工作負載和服務。 我們的容器基於Docker平臺,這是一種打包和交付軟體的高效方式,並使用AWS,Microsoft Azure和Google等領先雲提供商提供的託管Kubernetes服務。
-
數據攝取:為了使AI/ML模型不斷發展並發揮其潛力,數據必須從攝取流到多個下游系統,例如用於分析和監控的儀表板或用於模型培訓的基於Apache Hadoop的文件。 對於此功能,我們使用的是Apache Kafka,它提供了大量的實時數據攝取,集成,消息傳遞和pub/sub功能。 由此產生的多方數據攝取層提供毫秒延遲,保證傳輸和節流支援。
-
Low -延遲數據存儲:數據存儲在邊緣AI中扮演著重要角色,因為它需要亞秒級延遲,高吞吐量和低占用空間的數據存儲層,並且能夠同步回各種雲平臺以獲得存儲和歷史洞察。 在這裡,我們轉向Redis NoSQL數據庫系統。 NoSQL數據庫(如Redis)的結構比關係數據庫低。 此外,它們更具靈活性,擴展性更好,使其成為此應用的理想解決方案。
-
Data處理:Edge AI需要實時流處理,才能從不同來源捕獲事件,檢測復雜條件並實時發布到不同的端點。 我們使用的是Siddhi複合事件處理器(CEP)。 它是一個開放原始碼,雲原生,可擴展的微流CEP系統,能夠構建事件驅動型應用程式,用於實時分析,數據集成,通知管理和自適應決策等用例。
-
AI ë/ML Serving:Edge AI平臺通過Seldon.IO開放源碼框架在雲和邊緣基礎設施中實時提供完整的AI/ML部署和生命週期管理。 它支援多種異構工具包和語言。
-
Data可視化:使用Grafana儀表板和自定義開發的Node.js REST服務構建實時分析和儀表板的可視化,用於Redis數據存儲的實時查詢。
-
ML培訓和使用案例:Edge AI平臺支援最常用的ML框架,包括sci-kit-learn,TensorFlow,Keras和PyTorch,並提供完整的模型生命週期管理。 模型開發和測試完成後,將使用大型數據集對其進行培訓,打包並最終在邊緣無縫部署。
-
安全性和管理:安全性內置於整個邊緣AI平臺中。 它可以適應可自定義的安全框架,與客戶部署方案無關,並可跨多雲策略進行互操作。
-
Monitoring和編排:我們使用Argo CD等工具(Kubernetes的持續交付工具)通過CI/CD管道實現從雲到邊緣的編排。 我們的目標是使Edge AI應用程式部署和生命週期管理自動化,可審計且易於理解。
Platform參考架構
Now您已大致瞭解邊緣AI平臺中的技術,讓我們來看看它們如何結合在一起。 如下圖所示,邊緣AI平臺架構有三個主要部分:
-
數據攝取和處理
-
模型培訓
-
模型部署和服務
模型在雲上進行培訓,並在邊緣提供實時使用案例。 批量推斷在雲中進行,它與時間無關。
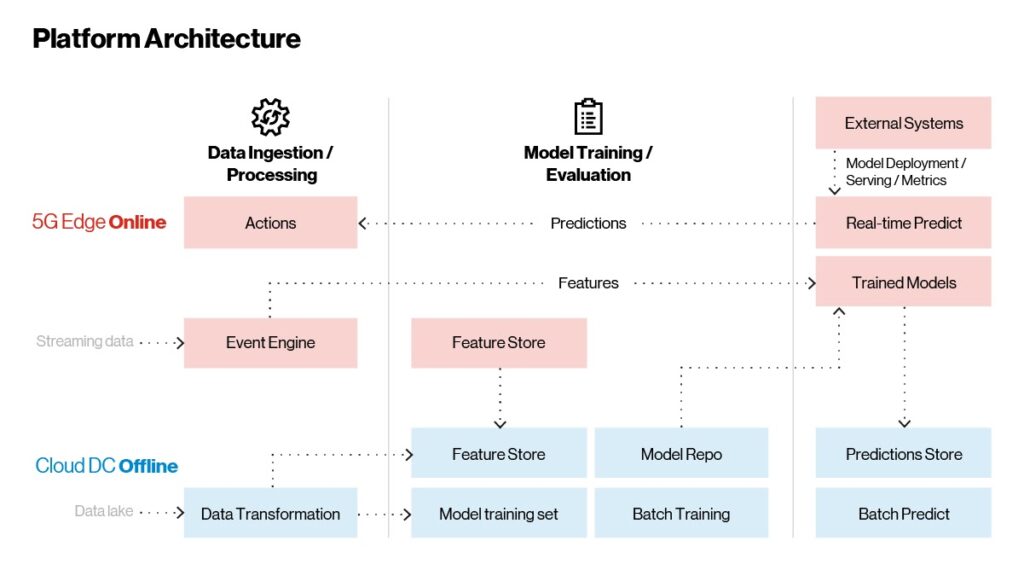
圖2 Edge AI—參考架構。
與可以實施,部署和偶爾更新的傳統應用程式不同,AI/ML應用程式不斷學習和改進。 該平臺中有三個主要工作流可幫助我們實現上述目標:
-
實時流工作流:這是應用程式主要功能的執行地點。 CEP捕獲和處理流數據,並智能掃描洞察或錯誤情況。 CEP從原始傳入數據流中提取特徵或值得注意的資訊,並將其發送到經過培訓的模型進行分析。 實時將預測發送回CEP規則引擎以進行聚合。 如果滿足某些條件,則會採取措施,例如關閉外部系統或提醒機器操作員可能出現故障。 所有實時預測和推斷都會傳遞到離線雲,以進行進一步的監控和評估。 此區域是根據不斷發展的數據更新功能的地方,使客戶能夠執行與機器學習管道集成的功能工程,如下圖4所述。
-
具有批量數據的按需工作流:推薦或個性化等外部系統可以將模型嵌入邊緣平臺。 通過嵌入式API閘道器,這些端點作為REST或gRPC端點公開,允許實時推斷調用和預測。
-
Historical Insights工作流:所有數據(原始數據,匯總數據和預測數據)都存儲在邊緣平臺的記憶體存儲中。 此數據通過雲連接器定期同步到雲平臺。 一旦數據置於雲中,它就會用於重新培訓和發展模型,以便不斷改進。 重新培訓的模型遵循從培訓到跟蹤到在雲上發布的整個生命週期。 然後,發布的模型將在持續部署中無縫地提供到邊緣平臺。 歷史洞察和批量推斷是在雲中完成的。
Edge AI攝取,處理和存儲
One AI/ML解決方案最重要的方面是能夠快速高效地採集和存儲數據。 對於某些應用,例如物聯網傳感器,數據量可能會很大。 為了讓您了解規模,IDC預測到2025年僅物聯網設備就會生成近80 zettabytes的數據。
為了支援最龐大的資料量,Edge AI平台(如下所示)支援多種攝取來源(物聯網,視訊,位置和感應器),通訊協定和攝取提供者。 它還支援高吞吐量,低延遲(每秒數百萬個事件,10毫秒延遲)。
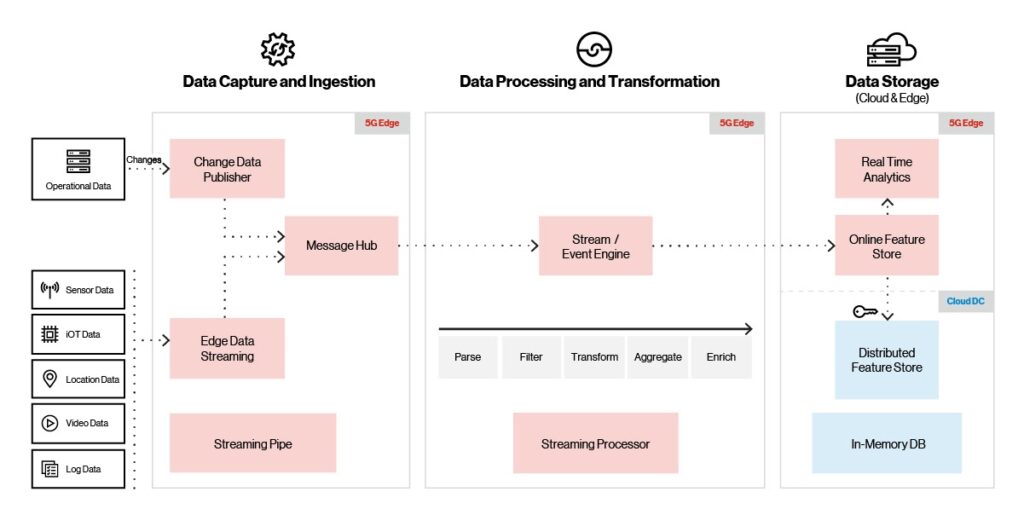
圖3 平臺攝取,處理和存儲。
當傳入的影片,物聯網或傳感器數據到達時,攝取層使用內置的節流功能來確保數據傳輸並防止溢出情況。 消息代理將傳入的數據傳送到流/事件引擎,在移至記憶體存儲庫之前,在該引擎中對其進行轉換,豐富或清理。 一旦數據存儲在記憶體存儲中,就會定期與分布式雲存儲同步。 可視化工具使用記憶體存儲中的數據提供實時分析和營運儀表板。
Machine學習管道
Machine學習依賴於算法;除非您是數據科學家或ML專家,否則這些算法很難理解和工作。 這就是機器學習框架所在,因此無需深入了解底層算法即可輕鬆開發ML模型。 雖然TensorFlow,PyTorch和sci-kit-learn無疑是當今最流行的ML框架,但將來可能不會如此,因此選擇適合預期應用的最佳框架非常重要。
為此,Edge AI平臺支援用於模型培訓,功能工程和服務的全套ML框架。 如下圖所示,Edge AI支援完整的模型生命週期管理,包括培訓,跟蹤,打包和服務。
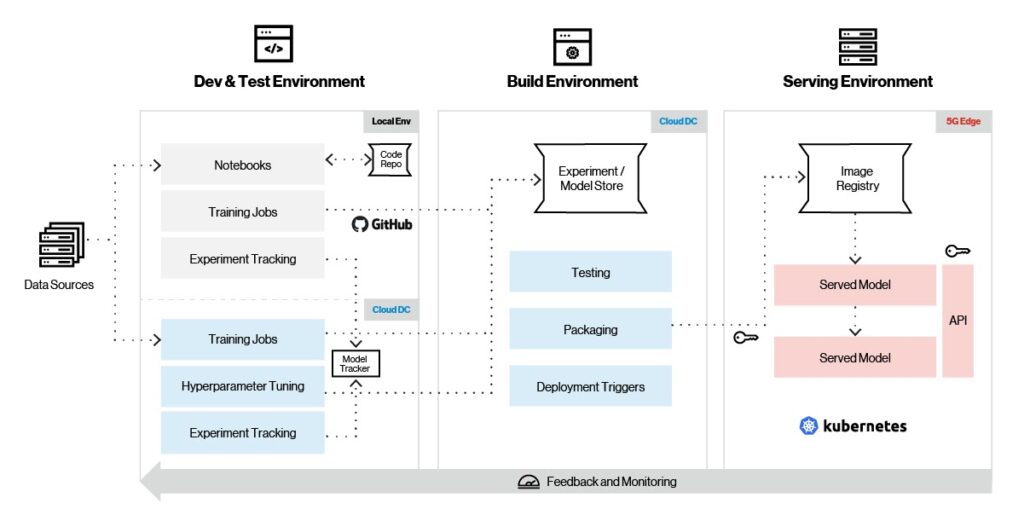
圖4 機器學習管道。
讓我們來看看Edge AI平臺上的典型機器學習工作流。 首先,您可以利用選擇的ML框架在本地環境中創建模型。 將模型組合在一起後,測試就會從小型資料集開始,並使用MLflow和Sagemaker等模型生命週期工具擷取實驗。 經過初始測試後,該模型可以在雲中接受有關大型數據集的培訓,以及超參數調整。 模型版本存儲在雲上的模型存儲庫中。
模型在雲中經過全面培訓後,下一步是在邊緣上進行初始部署以進行進一步測試。 然後,該模型經過最終測試,並根據邊緣上的某些部署觸發器,從雲中提取並在邊緣平臺上無縫部署。 不斷收集模型指標並將其發送到雲,以便進一步調整和發展模型。
Platform服務和監控
For邊緣AI平臺使用REST或gRPC端點實時為模型提供服務,在ML框架選擇和支援方面具有最大的靈活性。 服務和監控體系結構的概述如下所示。
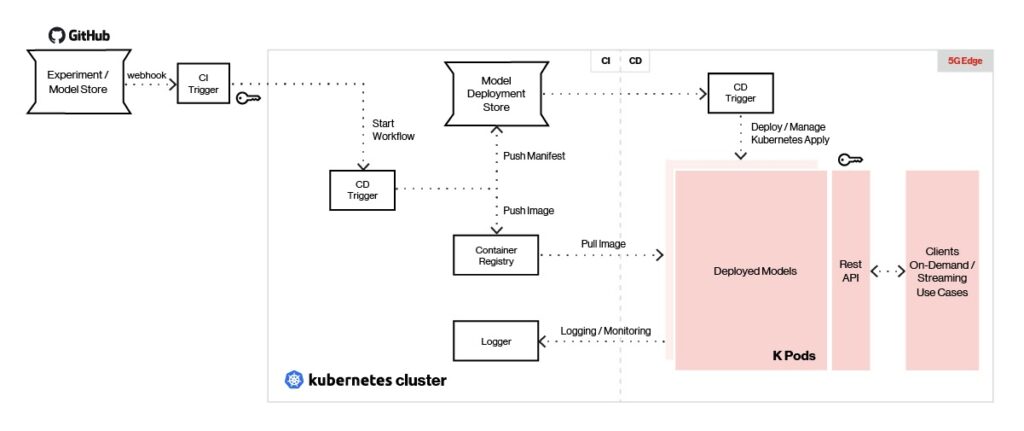
圖5 Edge AI可以為使用任何類型的機器學習框架創建的模型提供服務。
我們的平臺的持續集成工具(如Jenkins X)使模型可以使用部署觸發器將模型推送到邊緣的模型商店。 Argo CD等連續部署工具用於從存儲庫中提取模型映像,並將每個模型部署為獨立的POD。
部署的模型使用帶有REST/gRPC接口的Seldon提供,並且在API網關後面進行負載平衡。 客戶端向API閘道器發送REST/gRPC調用以生成預測。 模型管理和指標使用Seldon提供,日誌記錄和監控使用ELK Stack和/或Prometheus完成。
將人工智慧和計算能力與直接在網路邊緣的雲服務相結合,使組織能夠將日益復雜和變革性的實時企業用例推向市場。 如本文所述,Edge AI平臺有助於大規模營運實時企業AI,並顯著減少了將大量實時ML應用程式投入使用的障礙。 這使客戶能夠加快試點實施速度,並從試點有效地擴展到生產。
在本部落格系列的最後一期,我們將探討設計和部署基於Edge AI平臺的解決方案的流程,並提供預測分析,智能製造和物流領域的Edge AI解決方案的客戶示例。
Contact我們將詳細了解您的應用程式如何從我們的邊緣AI平臺中受益。
要閱讀本系列的第一個部落格,請單擊此處。





