

Fundo
Os CDNs e os provedores de nuvem fornecem grandes volumes de tráfego na Internet e empregam extensas ferramentas de monitoramento para garantir desempenho e confiabilidade. Estas incluem ferramentas que cobrem várias camadas de entrega de tráfego, tais como Rede, Servidor, Aplicação, etc. O TCP/IP representa a maior parte deste tráfego (enquanto O QUIC baseado em UDP está a aumentar globalmente, ainda é uma pequena fração do tráfego total em comparação com o TCP).
Os sockets são abstrações do sistema operativo que ligam a ligação cliente e servidor através da qual os dados são transmitidos. Os problemas de rede, portanto, são refletidos diretamente nos dados armazenados com cada socket. Por exemplo, o congestionamento na rede pode levar a tempos de resposta lentos e a um aumento nos tempos de ida e volta (RTT). Também é possível que a largura de banda da rede esteja disponível, mas a aplicação está sobrecarregada com demasiadas solicitações e não pode preencher o buffer com dados suficientes para utilizar totalmente a largura de banda disponível, resultando em uma anomalia limitada pela aplicação. Muitas vezes os servidores lidam com vários sockets ao mesmo tempo, o que pode levar à contenção de recursos colocando tensão nos recursos do sistema, como CPU e memória.
Assim, monitorar o desempenho dos soquetes de TCP em escala pode fornecer uma compreensão crítica dos comportamentos de tráfego, como tempos de resposta lentos ou conexões interrompidas, e identificar casos em que melhorias podem ser feitas.
Ferramentas existentes
O utilitário “ss” no Linux é uma ferramenta comum usada para obter estatísticas de socket. Semelhante ao “netstat”, o ss fornece um mecanismo mais rápido e mais flexível para obter informações permitindo filtros em estados de soquete, protocolos e endereços. Começámos também a nossa jornada de monitorização de tomadas com ss. Embora seja uma ferramenta poderosa para obter rapidamente uma lista de sockets e métricas relevantes, o principal desafio do ss é que ele pode consumir recursos significativos, especialmente quando usado em sistemas com um grande número de sockets. Isto pode afetar o desempenho do sistema e abrandar outros processos. Além disso, a saída ss não é ideal para análise, devido a uma chave inconsistente: Uso de valor, e complica significativamente a capacidade de transmitir dados recolhidos de milhares de servidores.
A nossa primeira versão da coleção de sockets usando ss foi um script bash executado em servidores de cache selecionados que exportamos a saída de ss -tcp -info” para um ficheiro. Este arquivo seria então rsync-ed para um host de bastião a partir do qual um script python iria lê-lo, analisar e inseri-lo no Elasticsearch. Isto fez o trabalho, mas não estava perto da escala de que precisávamos. A próxima iteração deste trabalho foi ter um script python ativo nos servidores de cache que seria chamado de uma interface HTTP e retornar as estatísticas agregadas para serem inseridas no cluster Elasticsearch. Este método escalou o gargalo de análise de um local central de back-office para o servidor de cache individual, mas resultou em grande utilização de memória em servidores com um número significativamente elevado de sockets. Em última análise, reconhecemos a necessidade de um substituto leve para a parte ss do sistema.
Os nossos principais requisitos para esta nova ferramenta eram que ela deveria ser leve e dimensionada para o grande número de tomadas que os nossos servidores CDN têm e ser capazes de transmitir dados de volta usando um mecanismo eficiente, como buffers de protocolo. A ferramenta tcp-info do MeasurementLab é um grande utilitário implementado no Golang. No entanto, é projetado para rastrear os mesmos soquetes ao longo do tempo. Dado o grande volume das nossas conexões de encaixe, fizemos uma escolha de design para não rastrear tomadas individuais. Em vez disso, peça que cada loop de votação seja independente, fornecendo um instantâneo do estado atual dos sockets abertos. O principal objetivo aqui é acompanhar o desempenho geral do sistema e não tomadas individuais.
Xtcp
Para resolver estes desafios, introduzimos o xtcp de código aberto (extract, export, Xray tcp). XTCP é um utilitário Golang para capturar e transmitir dados de socket em escala. O xTCP usa o NetLink para capturar informações de socket, empacota os dados em protobufs, e envia-os através de uma porta UDP (para ser eventualmente enviada para o Kafka, etc) ou escreve para o NSQ .
O NetLink fornece uma interface genérica para comunicação entre o espaço do utilizador e o espaço do kernel. As ferramentas de monitoramento de socket ss, tcp-info usam NetLink_INET_DIAG, parte da família de protocolos NetLink, para obter informações de socket do kernel para o espaço do usuário (nota da página man: NETLINK_INET_DIAG foi introduzido no Linux 2.6.14 e suportou os SOCKETS AF_INET e AF_INET6 apenas. No Linux 3,3, foi renomeado para NETLINK_SOCK_DIAG.
O xtcp extrai dados do kernel tcp inet_diag a taxas elevadas e exporta esses dados através de protobufs. Numa máquina com cerca de 120 k tomadas, as mensagens NetLink são cerca de 5-6MB, no entanto, a saída ascii de ss é de cerca de 60 MB. Além disso, o ss lê do kernel em blocos de cerca de 3KB por padrão. O xTCP lê blocos de 32 KB e, assim, minimiza as chamadas do sistema. O xTCP lê os dados do soquete NetLink simultaneamente usando vários trabalhadores para drenar a fila o mais rápido possível e analisa simultaneamente as mensagens do NetLink para streaming. Todas essas otimizações tornam a pegada do xTCP menor para ser executada em servidores de cache de produção.
Uso no Edgio
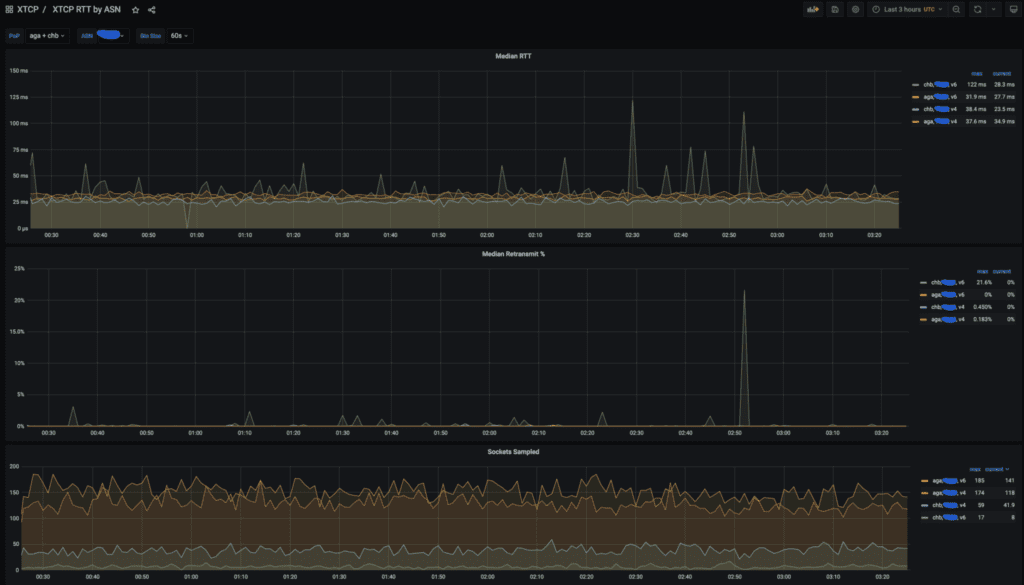
Utilizamos dados xtcp fortemente para analisar o desempenho do cliente. Normalmente, rastreamos o RTT e retransmite agregados por Ponto de Presença (Pop) e ASN.
Em contraste com a taxa de envelhecimento, o TTL permite-nos alterar a capacidade de cache de um determinado item. Durante a duração definida usando a função TTL, um item não envelhece enquanto está no disco, por isso é menos provável (mesmo muito improvável) ser despejado. Depois que o TTL expira, o item pode começar a envelhecer tanto da maneira tradicional de usar as UCRs, como com o envelhecimento rápido ou com o envelhecimento lento (dependendo de como o operador o configura). Na figura abaixo, o TTL com envelhecimento lento manteve um item no disco ao ponto de não ultrapassar o limite de despejo de cache. No lado oposto, o TTL assegurou que um fluxo de vídeo ao vivo era armazenado em cache durante, pelo menos, a duração do evento, mas depois disso foi rapidamente removido do disco usando o envelhecimento rápido.
Um exemplo de painel xtcp mostrando RTT, retransmite e número de tomadas amostradas para POPS AGA e CHB para um grande provedor dos EUA.
Num post anterior, apresentámos o nosso canal para o ajuste dinâmico do controlo de congestionamento, para permitir automaticamente a BBR para clientes com baixo desempenho e onde sabemos que o mecanismo da BBR seria mais útil. Os dados xTCP são a principal fonte para a análise.
Estamos constantemente a encontrar novas formas de usar os dados xTCP para responder a questões complexas, como o impactos do congestionamento, e aprendizagem automática para prever o desempenho e detetar anomalias. Planeamos relatar essa análise de dados de tomadas num futuro post no blog.
Hoje o xtcp junta-se ao vFlow (sflow, netflow, ipfix collector) no nosso conjunto de ferramentas de monitorização de rede de código aberto. Esperamos que isso sirva a comunidade de monitoramento do desempenho da infraestrutura para a coleta de dados de soquete e esteja ansioso pela participação ativa em levar essa ferramenta mais longe.
Confirmação
O sucesso e a ampla usabilidade do xTCP são resultado de contribuições de indivíduos e equipas de toda a Edgio. Gostaríamos de agradecer especialmente a David Seddon, que é o desenvolvedor inicial do xTCP. Um agradecimento especial a todos os revisores de código internos e colaboradores por testar, ingerir, painéis e feedback sobre o xTCP.





