

Hintergrund
CDNs und Cloud-Anbieter stellen große Datenverkehrsmengen im Internet bereit und setzen umfangreiche Überwachungstools ein, um Leistung und Zuverlässigkeit zu gewährleisten. Dazu gehören Tools, die verschiedene Ebenen der Datenverkehrsbereitstellung abdecken, z. B. Netzwerk, Server, Anwendung usw. TCP/IP macht den Großteil dieses Datenverkehrs aus (während UDP-basiertes QUIC weltweit auf dem Vormarsch ist, ist es im Vergleich zu TCP immer noch ein kleiner Bruchteil des gesamten Datenverkehrs).
Sockets sind Abstraktionen des Betriebssystems, die die Client- und Serververbindung verbinden, über die die Daten übertragen werden. Netzwerkprobleme spiegeln sich daher direkt in den Daten wider, die mit jedem Socket gespeichert werden. So kann beispielsweise eine Überlastung im Netzwerk zu langsamen Reaktionszeiten und einer Erhöhung der Round Trip Times (RTT) führen. Es ist auch möglich, dass Netzwerkbandbreite verfügbar ist, die Anwendung jedoch mit zu vielen Anforderungen überfordert ist und den Puffer nicht mit genügend Daten füllen kann, um die verfügbare Bandbreite vollständig auszulasten, was zu einer Anomalie führt, die auf die Anwendung beschränkt ist. Oft verarbeiten Server mehrere Sockets gleichzeitig, was zu Ressourcenkonflikten führen kann, wodurch Systemressourcen wie CPU und Arbeitsspeicher belastet werden.
Die Überwachung der Leistung von TCP-Sockets in großem Maßstab kann daher ein kritisches Verständnis des Datenverkehrsverhaltens, wie z. B. langsame Antwortzeiten oder unterbrochene Verbindungen, liefern und Fälle identifizieren, in denen Verbesserungen vorgenommen werden können.
Vorhandene Tools
Das Dienstprogramm „ss“ in Linux ist ein gängiges Tool, mit dem Socket-Statistiken abgerufen werden. Ähnlich wie „netstat“ bietet ss einen schnelleren und flexibleren Mechanismus zum Abrufen von Informationen, indem Filter für Socket-status, Protokolle und Adressen zugelassen werden. Wir begannen auch unsere Reise zur Socket-Überwachung mit ss. Es ist zwar ein leistungsstarkes Tool, um schnell eine Liste von Sockets und relevanten Metriken zu erhalten, aber die größte Herausforderung von ss besteht darin, dass es erhebliche Ressourcen verbrauchen kann, insbesondere wenn es auf Systemen mit einer großen Anzahl von Sockets verwendet wird. Dies kann die Systemleistung beeinträchtigen und andere Prozesse verlangsamen. Außerdem ist die ss-Ausgabe aufgrund der inkonsistenten Nutzung des Schlüssels nicht ideal für das Parsen und erschwert die Möglichkeit, gesammelte Daten von Tausenden von Servern zu streamen.
Unsere erste Version der Socket-Sammlung, die ss verwendet, war ein Bash-Skript, das auf ausgewählten Cache-Servern ausgeführt wurde und die Ausgabe von „ss –tcp –info“ in eine Datei exportiert wird. Diese Datei wird dann an einen Bastion-Host weitergeleitet, von dem aus ein Python-Skript sie liest, parst und in ElasticSearch einfügt. Das hat die Arbeit erledigt, aber es war nicht annähernd so groß wie wir es brauchten. Die nächste Iteration dieser Arbeit bestand darin, ein Python-Skript auf den Cache-Servern live zu halten, das von einer HTTP-Schnittstelle aufgerufen wird und die aggregierten Statistiken zurückgibt, die in das ElasticSearch-Cluster eingefügt werden. Diese Methode skalierte den Parsing-Engpass von einem zentralen Back-Office-Speicherort auf den einzelnen Cache-Server, führte aber zu einer hohen Speicherauslastung auf Servern mit einer deutlich hohen Anzahl von Sockets. Letztendlich erkannten wir die Notwendigkeit eines leichten Austauschs für den ss-Teil des Systems.
Unsere wichtigsten Anforderungen an dieses neue Tool waren, dass es leicht sein und an die große Anzahl von Sockets unserer CDN-Server skalieren sollte und Daten mithilfe eines effizienten Mechanismus wie Protokollpuffern zurückstreamen kann. Das TCP-Info-Tool von MeasurementLab ist ein großartiges Dienstprogramm, das in Golang implementiert wurde. Es ist jedoch für die Verfolgung derselben Buchsen im Zeitverlauf konzipiert. Aufgrund des großen Volumens unserer Buchsenverbindungen haben wir uns entschieden, einzelne Buchsen nicht zu verfolgen. Stattdessen müssen alle Polling Loop unabhängig sein, sodass ein Snapshot des aktuellen Status der geöffneten Sockets bereitgestellt wird. Das Hauptziel besteht darin, die Gesamtleistung des Systems und nicht die einzelnen Sockets zu verfolgen.
XTCP
Um diese Herausforderungen zu lösen, führen wir xTCP-Open-Source (Extract, Export, Xray TCP) ein. XTCP ist ein Golang-Utility zum Erfassen und Streamen von Socket-Daten im Maßstab. XTCP verwendet Netlink, um Socket-Informationen zu erfassen, die Daten in Protobufs zu verpacken und über einen UDP-Port (um schließlich an Kafka usw. zu senden) oder an NSQ zu schreiben.
NetLink bietet eine generische Schnittstelle für die Kommunikation zwischen Benutzerbereich und Kernel-Bereich. Socket-Überwachungstools ss, tcp-info verwenden NETLINK_INET_DIAG, ein Teil der Netlink-Protokollfamilie, um Socket-Informationen vom Kernel in den Benutzerbereich abzurufen (Hinweis: NETLINK_INET_DIAG wurde in Linux 2.6.14 eingeführt und unterstützte nur AF_INET- und AF_INET6-SOCKETS. In Linux 3,3 wurde es in NETLINK_SOCK_DIAG umbenannt und erweitert, um AF_UNIX-SOCKETS zu unterstützen.).
XTCP extrahiert Kernel-TCP-INET_DIAG-Daten mit hoher Rate und exportiert diese Daten über Protobufs. Auf einem Computer mit ca. ~120k Sockets betragen die Netlink-Nachrichten ca. ~5-6MB, die ASCII-Ausgabe von ss beträgt jedoch ca. ~60MB. Außerdem liest ss standardmäßig aus dem Kernel in ca. 3kB-Blöcken. XTCP liest 32-KB-Chunks und minimiert somit Systemaufrufe. XTCP liest Netlink Socket-Daten gleichzeitig mit mehreren Workern, um die Queue so schnell wie möglich zu leeren, und analysiert gleichzeitig die Netlink-Nachrichten für das Streaming. All diese Optimierungen machen den Platzbedarf von xTCP für die Ausführung auf Produktionscacheservern kleiner.
Verwendung bei Edgio
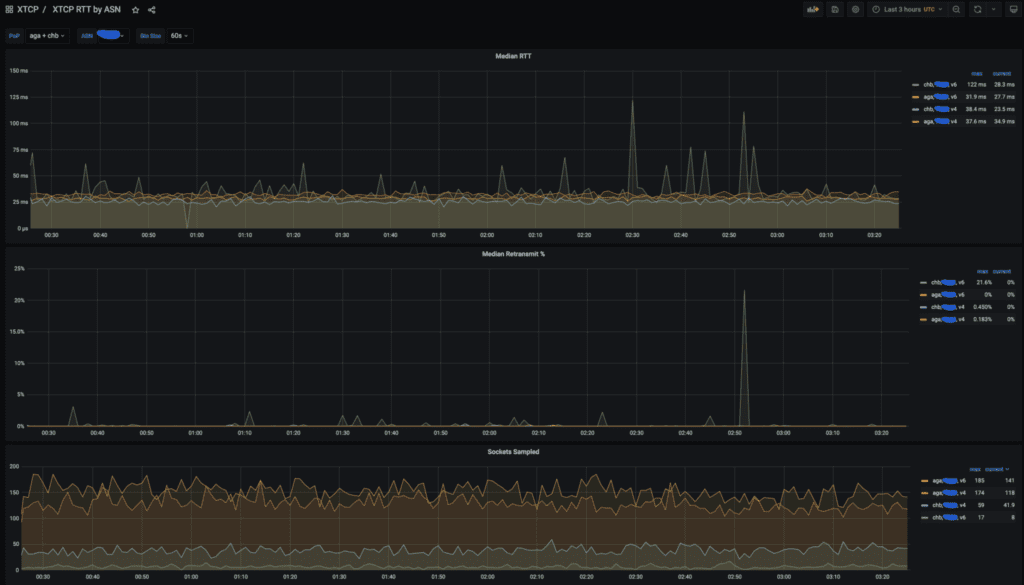
Wir nutzen xTCP-Daten stark, um die Client-Performance zu analysieren. In der Regel verfolgen wir RTT und Neuübertragungen aggregiert nach POP (Point of Presence) und ASN.
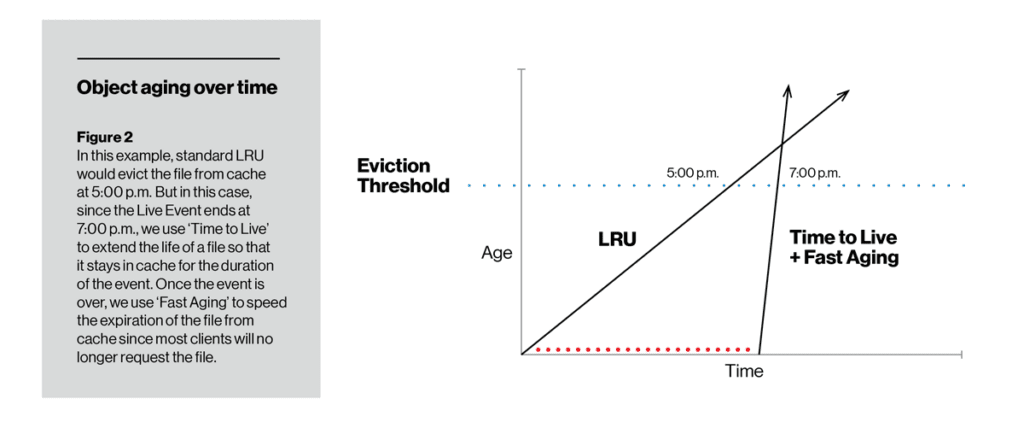
Im Gegensatz zur Fälligkeitsrate können wir mit TTL die Cachefähigkeit eines bestimmten Elements ändern. Während der mit der TTL-Funktion eingestellten Dauer altert ein Element nicht, während es sich auf der Festplatte befindet, so dass es weniger wahrscheinlich (sogar sehr unwahrscheinlich) ist, dass es vertrieben wird. Nach Ablauf der TTL kann das Element entweder auf die herkömmliche LRU-Art oder mit schneller oder langsamer Alterung (je nach Konfiguration durch den Bediener) altern. In der folgenden Abbildung behielt TTL mit langsamer Alterung ein Element auf der Festplatte so weit, dass es den Schwellenwert für das Auswerfen des Cache nicht überschritten hat. Am anderen Ende sorgte TTL dafür, dass ein Live-Video-Stream mindestens für die Dauer des Ereignisses zwischengespeichert wurde, danach aber schnell durch schnelles Altern von der Festplatte entfernt wurde.
Ein Beispiel für ein xTCP-Dashboard, das RTT, Neuübertragungen und die Anzahl der Sockets anzeigt, die für POPS AGA und CHB für einen großen US-Anbieter abgetastet wurden.
In einem vorherigen Blogbeitrag haben wir unsere Pipeline für die dynamische Optimierung der Engpasskontrolle vorgestellt, um BBR automatisch für Kunden zu aktivieren, die eine unterdurchschnittliche Leistung aufweisen und bei denen wir wissen, dass der BBR-Mechanismus am nützlichsten wäre. XTCP-Daten sind die Hauptquelle für die Analyse.
Wir finden ständig neue Wege, um die xTCP-Daten zur Beantwortung komplexer Fragen zu nutzen, wie z. B. die Auswirkungen von Engpässen und maschinelles Lernen zur Vorhersage der Leistung und Erkennung von Anomalien. Wir planen, über eine solche Analyse von Socket-Daten in einem zukünftigen Blogbeitrag Bericht zu erstatten.
Heute wird xTCP mit vFlow (sflow, netflow, ipfix Collector) in unserer Suite von Open Source-Netzwerküberwachungstools verbunden. Wir hoffen, dass dies der Community zur Überwachung der Infrastrukturleistung bei der Erfassung von Socket-Daten dient und freuen uns auf eine aktive Beteiligung an der Weiterentwicklung dieses Tools.
Bestätigung
Der Erfolg und die umfassende Benutzerfreundlichkeit von xTCP sind das Ergebnis der Beiträge von Einzelpersonen und Teams in Edgio. Wir möchten uns besonders bei David Seddon bedanken, der der ursprüngliche Entwickler von xTCP ist. Ein besonderer Dank gilt allen internen Codeüberprüfern und Beitragenden für Tests, Ingesting, Dashboards und Feedback zu xTCP.





