

Sfondo
Le CDN e i provider di servizi cloud forniscono grandi volumi di traffico su Internet e utilizzano strumenti di monitoraggio completi per garantire prestazioni e affidabilità. Questi includono strumenti che coprono vari livelli di distribuzione del traffico, come rete, server, applicazioni, ecc. Il protocollo TCP/IP rappresenta la maggior parte di questo traffico (mentre QUIC basato su UDP è in aumento a livello globale, è comunque una piccola frazione del traffico totale rispetto al protocollo TCP).
I socket sono astrazioni del sistema operativo che collegano la connessione client e server su cui vengono trasmessi i dati. I problemi di rete, quindi, si riflettono direttamente nei dati memorizzati con ogni socket. Ad esempio, la congestione della rete può portare a tempi di risposta lenti e a un aumento dei tempi di round trip (RTT). È anche possibile che la larghezza di banda della rete sia disponibile, ma l’applicazione è sovraccarica di troppe richieste e non può riempire il buffer con dati sufficienti per utilizzare completamente la larghezza di banda disponibile, con conseguente anomalia limitata dall’applicazione. Spesso i server gestiscono più socket contemporaneamente, il che può portare a conflitti di risorse che mettono a dura prova le risorse di sistema come CPU e memoria.
Pertanto, il monitoraggio delle prestazioni dei socket TCP su vasta scala può fornire una comprensione critica dei comportamenti del traffico, come tempi di risposta lenti o interruzioni delle connessioni, e identificare i casi in cui è possibile apportare miglioramenti.
Strumenti esistenti
“L’utility “ss” in Linux è uno strumento comune utilizzato per ottenere statistiche socket.” “Simile a “netstat”, ss fornisce un meccanismo più veloce e flessibile per ottenere informazioni consentendo filtri su stati socket, protocolli e indirizzi.” Abbiamo iniziato il nostro viaggio di monitoraggio dei socket anche con ss. Sebbene sia uno strumento potente per ottenere rapidamente un elenco di socket e metriche pertinenti, la sfida principale di ss è che può consumare risorse significative, soprattutto se utilizzato su sistemi con un gran numero di socket. Ciò può influire sulle prestazioni del sistema e rallentare altri processi. Inoltre, l’output ss non è ideale per l’analisi, a causa di una chiave incoerente: L’utilizzo del valore e complica notevolmente la capacità di trasmettere in streaming i dati raccolti da migliaia di server.
La nostra prima versione di socket Collection che utilizza ss era uno script bash eseguito su server cache selezionati, che esporta l’output di “ss –tcp –info” in un file. Questo file sarebbe quindi rsync-ed in un host bastion da cui uno script Python lo leggesse, lo analizzasse e lo inserisse in Elasticsearch. Questo ha portato a termine il lavoro, ma non era neanche lontanamente vicino alla scala di cui avevamo bisogno. La successiva iterazione di questo lavoro è stata quella di avere uno script Python live sui server cache che sarebbe stato chiamato da un’interfaccia HTTP e restituire le statistiche aggregate per essere inserite nel cluster Elasticsearch. Questo metodo ha scalato il collo di bottiglia dell’analisi da una posizione centrale di back-Office al singolo server cache, ma ha comportato un elevato utilizzo della memoria sui server con un numero di socket significativamente elevato. In definitiva, abbiamo riconosciuto la necessità di una sostituzione leggera della porzione ss del sistema.
I nostri requisiti principali per questo nuovo strumento erano che fosse leggero e scalabile in base al gran numero di socket che i nostri server CDN hanno e che fosse in grado di rigenerare i dati utilizzando un meccanismo efficiente come i buffer di protocollo. Lo strumento TCP-info di MeasurementLab è una grande utility implementata in Golang. Tuttavia, è progettato per monitorare gli stessi socket nel tempo. Dato il grande volume dei nostri collegamenti femmina, abbiamo scelto di non tracciare i singoli connettori femmina. Al contrario, ogni ciclo di polling deve essere indipendente, fornendo un’istantanea dello stato corrente dei socket aperti. L’obiettivo principale è monitorare le prestazioni complessive del sistema e non i singoli socket.
XTCP
Per risolvere queste sfide, introduciamo e approviamo xTCP (Extract, Export, Xray TCP) open source. XTCP è un’utility Golang che consente di acquisire e trasmettere in streaming i dati socket su larga scala. XTCP utilizza NetLink per acquisire informazioni socket, comprimere i dati in protobuf e inviarli tramite una porta UDP (per essere eventualmente inviati a Kafka, ecc.) o scrivere a NSQ.
NetLink fornisce un’interfaccia generica per la comunicazione tra lo spazio utente e lo spazio del kernel. Gli strumenti di monitoraggio socket ss, tcp-info utilizzano NETLINK_INET_DIAG, parte della famiglia di protocolli NetLink, per ottenere informazioni socket dal kernel nello spazio utente (nota da man page: NETLINK_INET_DIAG è stato introdotto in Linux 2.6.14 e supporta solo socket AF_INET e AF_INET6. In Linux 3,3, è stato rinominato NETLINK_SOCK_DIAG ed esteso per supportare i socket AF_UNIX.)
XTCP estrae i dati TCP INET_DIAG del kernel ad alta velocità ed esporta tali dati tramite protobuf. Su un computer con circa 120 socket, i messaggi NetLink sono circa 5-6 MB, tuttavia l’output ASCII di ss è di circa 60 MB. Inoltre, ss legge dal kernel in blocchi di ~3 KB per impostazione predefinita. XTCP legge i blocchi da 32 KB e riduce al minimo le chiamate di sistema. XTCP legge contemporaneamente i dati del socket NetLink utilizzando più lavoratori per scaricare la coda il più velocemente possibile e analizza contemporaneamente i messaggi NetLink per lo streaming. Tutte queste ottimizzazioni riducono l’ingombro di xTCP per essere eseguito su server cache di produzione.
Uso alla Edgio
Utilizziamo i dati xTCP in modo massiccio per analizzare le prestazioni dei client. Generalmente, teniamo traccia di RTT e ritrasmettiamo aggregati per punto di presenza (POP) e ASN.
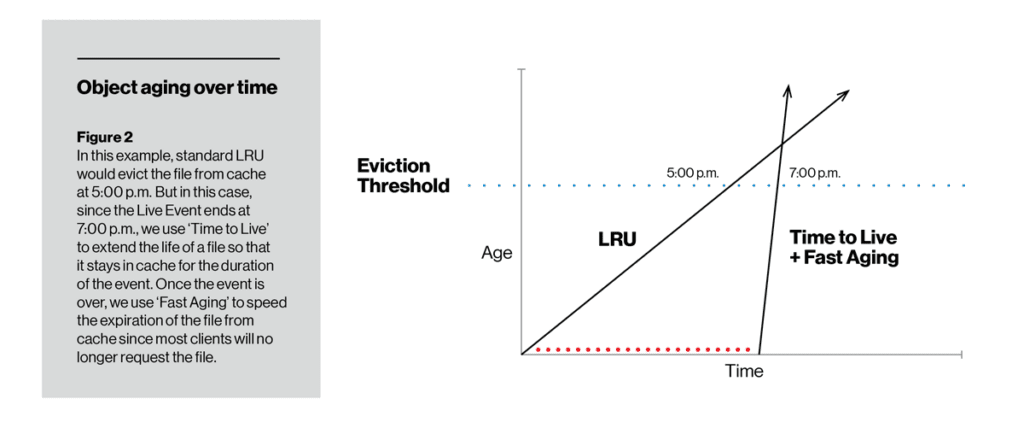
A differenza della velocità di invecchiamento, TTL ci consente di modificare la capacità di cache di un particolare elemento. Per la durata impostata utilizzando la funzione TTL, un elemento non invecchia mentre è sul disco, quindi è meno probabile (anche molto improbabile) che venga sfrattato. Una volta scaduto il TTL, l’articolo può iniziare a invecchiare nel modo tradizionale LRU o con invecchiamento rapido o lento (a seconda di come l’operatore lo configura). Nella figura riportata di seguito, il TTL con invecchiamento lento ha mantenuto un elemento sul disco fino al punto in cui non ha superato la soglia di sfratto della cache. All’estremità opposta, TTL ha garantito che un flusso video live fosse memorizzato nella cache per almeno la durata dell’evento, ma successivamente è stato rapidamente rimosso dal disco utilizzando il fast aging.
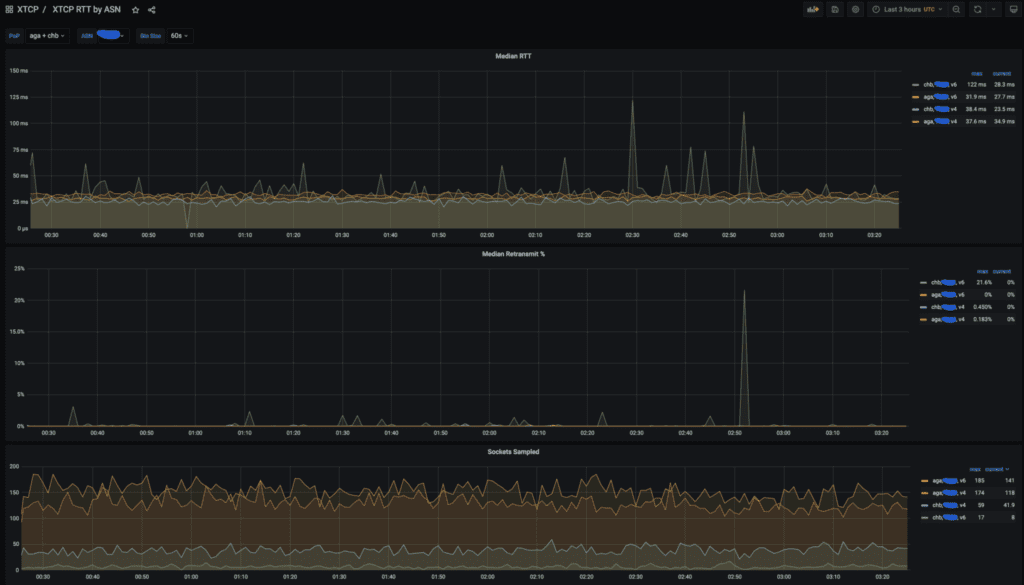
Un esempio di dashboard xTCP che mostra RTT, ritrasmissioni e numero di socket campionati per POP AGA e CHB per un grande provider statunitense.
In un precedente post sul blog, abbiamo presentato la nostra pipeline per l’ottimizzazione del controllo dinamico della congestione per abilitare automaticamente BBR per i clienti che hanno prestazioni inferiori e per i quali sappiamo che il meccanismo di BBR sarebbe più utile. I dati xTCP sono la fonte principale per l’analisi.
Siamo costantemente alla ricerca di nuovi modi per utilizzare i dati xTCP per rispondere a domande complesse come l’impatto della congestione e l’apprendimento automatico per prevedere le prestazioni e rilevare le anomalie. Abbiamo intenzione di riferire su tale analisi dei dati socket in un futuro post sul blog.
Oggi xTCP si unisce a vFlow (sflow, netflow, ipfix collector) nella nostra suite di strumenti di monitoraggio di rete open source. Ci auguriamo che ciò sia utile alla comunità di monitoraggio delle prestazioni dell’infrastruttura per la raccolta dei dati socket e siamo ansiosi di partecipare attivamente a questo strumento.
Conferma
Il successo e l’ampia usabilità di xTCP sono il risultato dei contributi di individui e team di Edgio. Vorremmo ringraziare in particolare David Seddon, che è lo sviluppatore iniziale di xTCP. Un ringraziamento speciale a tutti i revisori del codice interno e ai collaboratori per i test, l’acquisizione, i dashboard e il feedback su xTCP.





