

Le applicazioni di intelligenza artificiale aziendale in tempo reale in vari settori industriali richiedono una piattaforma di dati e informazioni ML IN tempo reale con interconnessione indipendente dal cloud. L’intelligenza artificiale edge di Verizon Media è una piattaforma appositamente progettata per aiutare i clienti all’intersezione tra la gestione dei dati e le operazioni di apprendimento automatico (MLOps), in modo che possano operare su un’infrastruttura eterogenea su scala globale. Il passaggio dell’intelligenza artificiale alla periferia della rete consente di prendere decisioni e azioni quasi in tempo reale. In questo modo si apre una gamma di applicazioni entusiasmanti e trasformative nei segmenti industriali e consumer, che abbiamo descritto nel primo post del blog di questa serie.
In molti modi, come spiegheremo, lo scopo dell’intelligenza artificiale perimetrale è quello di collegare tutti gli elementi necessari per progettare, sviluppare e implementare applicazioni commerciali di intelligenza artificiale all’edge della rete, in modo da consentire casi di utilizzo aziendali in tempo reale. Ciò include la nostra rete per la distribuzione dei contenuti (CDN), con soli 10-25 millisecondi di latenza per quasi tutti gli utenti Internet in tutto il mondo, la nostra tecnologia 5G in sede, un livello di piattaforma applicativa estensibile come servizio (aPaaS), la gestione dei dati cloud, la sicurezza completa e il monitoraggio e l’analisi approfonditi.
Fin dall’inizio del processo di sviluppo dell’intelligenza artificiale perimetrale, la nostra visione era quella di creare una piattaforma containerizzata leggera e indipendente dall’infrastruttura con un’interconnessione indipendente dal cloud per fornire dati attuabili in tempo reale e informazioni sull’apprendimento automatico all’edge della rete. Questa visione, a sua volta, ci ha aiutato a rispettare gli obiettivi e le decisioni tecnologiche per la piattaforma, come illustrato nella figura seguente.
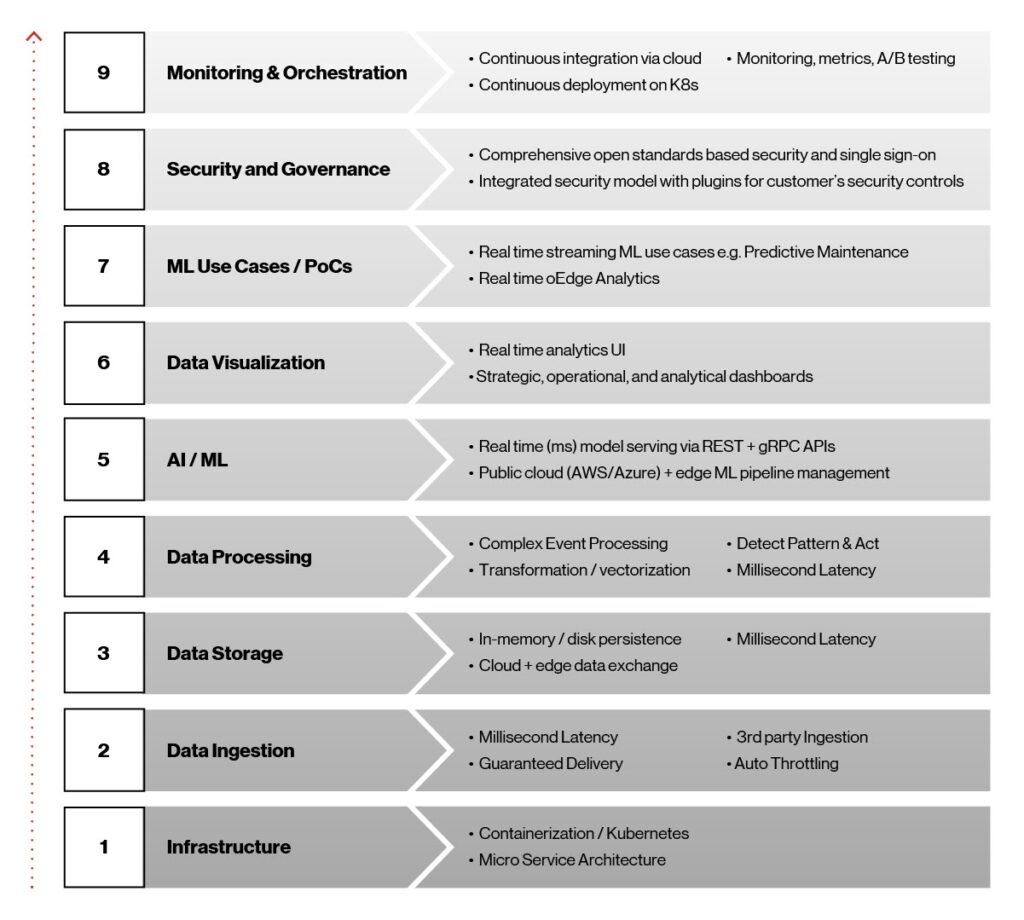
Figura 1. Elementi architettonici ai edge.
Questi nove elementi svolgono un ruolo essenziale nel rendere possibile la piattaforma ai Edge e sono fondamentali per il suo successo, poiché le soluzioni commerciali vengono distribuite in produzione. Diamo un’occhiata più da vicino a questi elementi, lavorando dal basso verso l’alto.
-
Infrastructure: Kubernetes e Containers erano le scelte più ovvie per alta disponibilità, latenza ultra bassa e rapida implementazione di modelli ai/ML all’edge. Kubernetes indipendente dall’infrastruttura è una piattaforma open source portatile, estendibile per la gestione di carichi di lavoro e servizi containerizzati. I nostri container sono basati sulla piattaforma Docker, un modo efficiente per creare pacchetti e distribuire software e lavorare sui servizi Kubernetes gestiti forniti da provider cloud leader come AWS, Microsoft Azure e Google.
-
Acquisizione dei dati: Affinché i modelli ai/ML evolvano e raggiungano il loro potenziale, i dati devono passare dall’acquisizione a più sistemi downstream, come un dashboard per l’analisi e il monitoraggio o file basati su Apache Hadoop per la formazione sui modelli. Per questa funzione, utilizziamo Apache Kafka, che offre in tempo reale l’acquisizione dei dati, l’integrazione, la messaggistica e pub/sub su larga scala. Il livello di acquisizione dati multi-party risultante fornisce latenza in millisecondi, delivery garantita e supporto per la limitazione.
-
Storage dei dati a latenza Low: Lo storage dei dati svolge un ruolo importante nell’intelligenza artificiale edge, a causa della necessità di latenza inferiore al secondo, throughput elevato e un livello di storage dei dati a ingombro ridotto, oltre alla possibilità di sincronizzare le varie piattaforme cloud per lo storage e le informazioni storiche. Qui, ci siamo rivolti al sistema di database Redis NoSQL. I database NoSQL, come Redis, sono meno strutturati dei database relazionali. Inoltre, sono più flessibili e possono scalare meglio, il che li rende la soluzione ideale per questa applicazione.
-
Data elaborazione: L’elaborazione del flusso in tempo reale è necessaria in Edge ai per acquisire eventi da diverse fonti, rilevare condizioni complesse e pubblicare su diversi endpoint in tempo reale. Stiamo utilizzando il Siddhi Complex Event Processor (CEP). Si tratta di un sistema CEP open source, cloud-native, scalabile e micro-streaming in grado di creare applicazioni basate su eventi per casi di utilizzo quali analisi in tempo reale, integrazione dei dati, gestione delle notifiche e processi decisionali adattivi.
-
AI/ML Serving: La piattaforma ai Edge fornisce l’implementazione ai/ML completa e la gestione del ciclo di vita su cloud e infrastruttura perimetrale in tempo reale tramite il framework open source Seldon.io. Supporta più linguaggi e toolkit eterogenei.
-
Data visualizzazione: Le visualizzazioni per l’analisi in tempo reale e il dashboarding vengono create utilizzando il dashboard di Grafana e i servizi REST Node.js sviluppati su misura per le query in tempo reale degli archivi di dati Redis.
-
ML formazione e casi di utilizzo: La piattaforma Edge ai supporta i framework ML più diffusi, tra cui sci-kit-Learn, TensorFlow, Keras e PyTorch e fornisce una gestione completa del ciclo di vita del modello. Una volta sviluppati e testati, i modelli vengono addestrati utilizzando set di dati di grandi dimensioni, confezionati e infine implementati senza problemi all’edge della rete.
-
sicurezza e governance: La sicurezza è integrata nell’intera piattaforma di intelligenza artificiale Edge. Può ospitare framework di sicurezza personalizzabili, è indipendente dagli scenari di distribuzione dei clienti ed è interoperabile in una strategia multi-cloud.
-
Monitoring e orchestrazione: Otteniamo l’orchestrazione dal cloud alla periferia tramite la pipeline ci/CD utilizzando strumenti come Argo CD, uno strumento di consegna continua per Kubernetes. Il nostro obiettivo era rendere l’implementazione delle applicazioni ai edge e la gestione del ciclo di vita automatizzata, verificabile e facile da capire.
Platform architettura di riferimento
Now avere una panoramica delle tecnologie in gioco nella piattaforma Edge ai, vediamo come si integrano. Come illustrato nella figura seguente, l’architettura della piattaforma ai Edge è composta da tre parti principali:
-
Acquisizione ed elaborazione dei dati
-
Formazione sui modelli
-
Implementazione e fornitura di modelli
I modelli sono addestrati sul cloud e serviti all’edge della rete per casi di utilizzo in tempo reale. La deduzione batch, che non dipende dal tempo, avviene nel cloud.
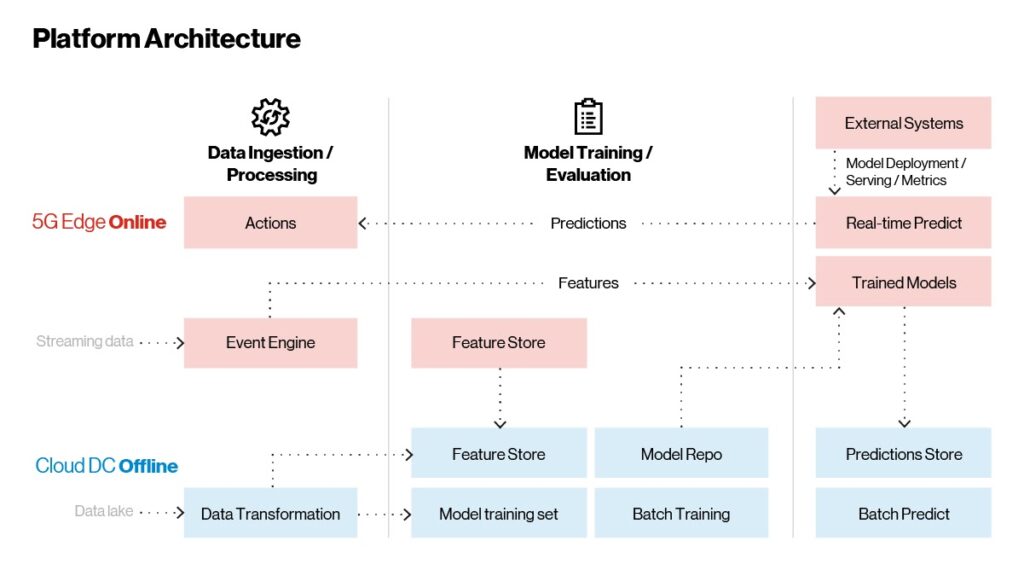
Figura 2. Intelligenza artificiale edge – architettura di riferimento.
A differenza delle applicazioni tradizionali, che possono essere implementate, implementate e occasionalmente aggiornate, le applicazioni ai/ML apprendono e migliorano costantemente. Nella piattaforma sono presenti tre flussi di lavoro principali che ci aiutano a realizzare quanto sopra:
-
Flusso di lavoro in tempo reale: È qui che si svolge la funzione principale dell’applicazione. Un CEP acquisisce ed elabora i dati in streaming ed esegue una scansione intelligente per individuare informazioni o condizioni di errore. Il CEP estrae le funzioni o le informazioni degne di nota dal flusso non elaborato dei dati in entrata e le invia ai modelli addestrati per l’analisi. In tempo reale, le previsioni vengono rinviate al motore di regole CEP per l’aggregazione. Se vengono soddisfatte determinate condizioni, vengono intraprese delle azioni, ad esempio l’arresto di un sistema esterno o l’avviso di un potenziale guasto all’operatore della macchina. Tutte le previsioni e le deduzioni in tempo reale vengono trasmesse al cloud offline per un ulteriore monitoraggio e valutazione. In quest’area le funzioni vengono aggiornate in base all’evoluzione dei dati, consentendo ai clienti di eseguire la progettazione delle funzioni integrata con la pipeline di apprendimento automatico descritta nella Figura 4 riportata di seguito.
-
Flusso di lavoro on demand con batch di dati: Sistemi esterni come consigli o personalizzazione possono incorporare modelli all’interno della piattaforma edge. Questi sono esposti come endpoint REST o gRPC tramite un gateway API incorporato, consentendo chiamate di inferenza e previsioni in tempo reale.
-
Flusso di lavoro delle informazioni Historical: Tutti i dati (grezzi, aggregati e previsioni) vengono memorizzati in un archivio in memoria nella piattaforma edge. Questi dati vengono sincronizzati periodicamente con le piattaforme cloud tramite connettori cloud. Una volta che i dati atterrano nel cloud, vengono utilizzati per riqualificare ed evolvere i modelli per il miglioramento continuo. I modelli riformati seguono un ciclo di vita completo, dalla formazione al monitoraggio fino alla pubblicazione sul cloud. I modelli pubblicati vengono quindi serviti senza problemi alla piattaforma perimetrale in un’implementazione continua. Le informazioni storiche e la deduzione in batch vengono eseguite nel cloud.
Ingestione, elaborazione e archiviazione ai margini dell’intelligenza artificiale
One degli aspetti più importanti di una soluzione ai/ML è la capacità di acquisire e memorizzare i dati con velocità ed efficienza. I volumi di dati possono essere enormi per alcune applicazioni, come i sensori IoT. Per darvi un’idea della scalabilità, IDC prevede che i soli dispositivi IoT genereranno quasi 80 zettabyte di dati entro il 2025.
Per supportare anche i volumi di dati più massicci, la piattaforma Edge ai, come mostrato di seguito, supporta più fonti di acquisizione (IoT, video, posizione e sensori), protocolli e provider di acquisizione. Supporta inoltre un throughput elevato con bassa latenza (milioni di eventi/secondo con latenza di 10 ms).
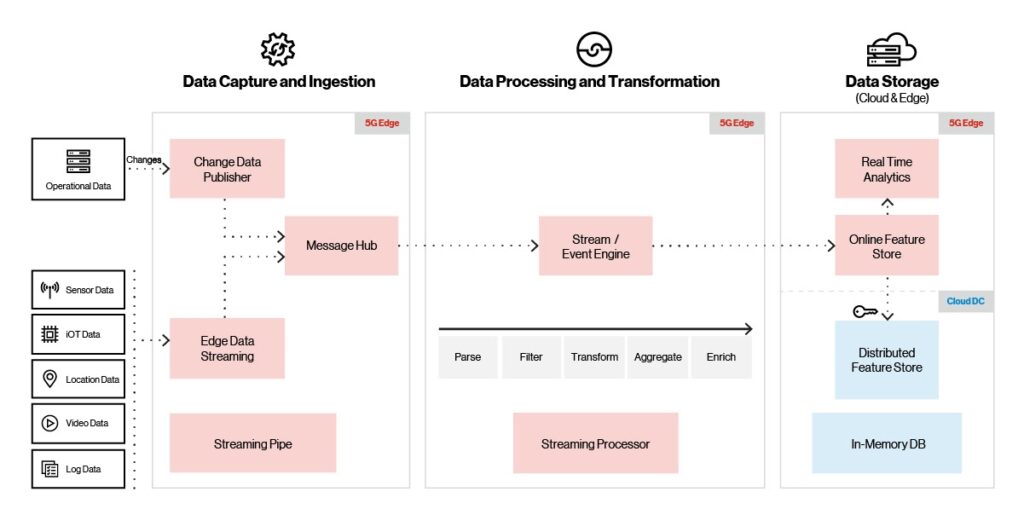
Figura 3. Acquisizione, elaborazione e archiviazione della piattaforma.
All’arrivo dei dati video, IoT o dei sensori in arrivo, il livello di acquisizione utilizza la limitazione integrata per garantire la consegna dei dati e prevenire le condizioni di overflow. Un broker di messaggi consegna i dati in arrivo al motore di flusso/evento, dove vengono trasformati, arricchiti o puliti prima di passare all’archivio di memoria. Una volta che i dati sono nel negozio di memoria, vengono periodicamente sincronizzati con il cloud store distribuito. Gli strumenti di visualizzazione forniscono analisi in tempo reale e dashboard operativi utilizzando i dati presenti nell’archivio di memoria.
Machine pipeline di apprendimento
Machine apprendimento si basa su algoritmi; a meno che tu non sia uno scienziato dei dati o un esperto DI ML, questi algoritmi sono molto complicati da capire e lavorare. È qui che entra in gioco un framework di apprendimento automatico, rendendo possibile sviluppare facilmente modelli ML senza una profonda comprensione degli algoritmi DI base. Mentre TensorFlow, PyTorch e sci-kit-Learn sono probabilmente i framework ML più popolari oggi, ciò potrebbe non essere il caso in futuro, quindi è importante scegliere il framework migliore per l’applicazione prevista.
A tal fine, la piattaforma Edge ai supporta una gamma completa di framework ML per la formazione dei modelli, l’ingegneria delle funzionalità e la fornitura. Come illustrato nella figura seguente, Edge ai supporta la gestione completa del ciclo di vita del modello, tra cui formazione, monitoraggio, packaging e fornitura.
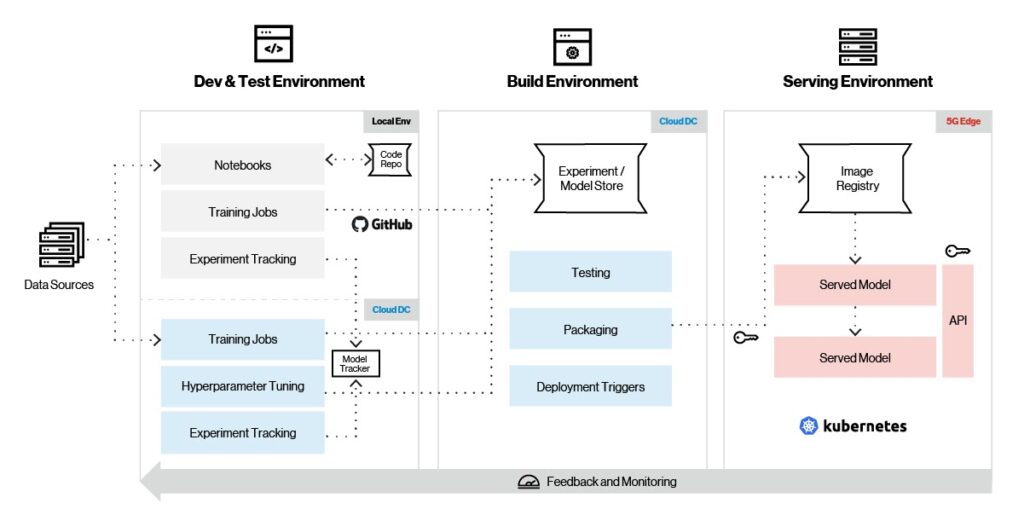
Figura 4. Pipeline di apprendimento automatico.
Esaminiamo il tipico flusso di lavoro di apprendimento automatico sulla piattaforma di intelligenza artificiale Edge. Innanzitutto, si utilizza il framework ML preferito per creare un modello in un ambiente locale. Una volta riunito il modello, il test inizia con piccoli set di dati e gli esperimenti vengono acquisiti utilizzando strumenti del ciclo di vita del modello come MLflow e Sagemaker. Dopo il test iniziale, il modello è pronto per essere addestrato nel cloud su set di dati più grandi, insieme alla regolazione degli iperparametri. Le versioni dei modelli sono memorizzate negli archivi dei modelli sul cloud.
Una volta che il modello è stato completamente addestrato nel cloud, il passaggio successivo è la distribuzione iniziale all’edge della rete per ulteriori test. Il modello viene quindi sottoposto a test e packaging finali, e in base a determinati trigger di distribuzione all’edge, viene estratto dal cloud e distribuito senza problemi sulla piattaforma edge. Le metriche dei modelli vengono raccolte continuamente e inviate al cloud per un’ulteriore ottimizzazione ed evoluzione dei modelli.
Platform servizio e monitoraggio
For massima flessibilità nella selezione e nel supporto del framework ML, la piattaforma Edge ai utilizza endpoint REST o gRPC per servire i modelli in tempo reale. Di seguito è riportata una panoramica dell’architettura di servizio e monitoraggio.
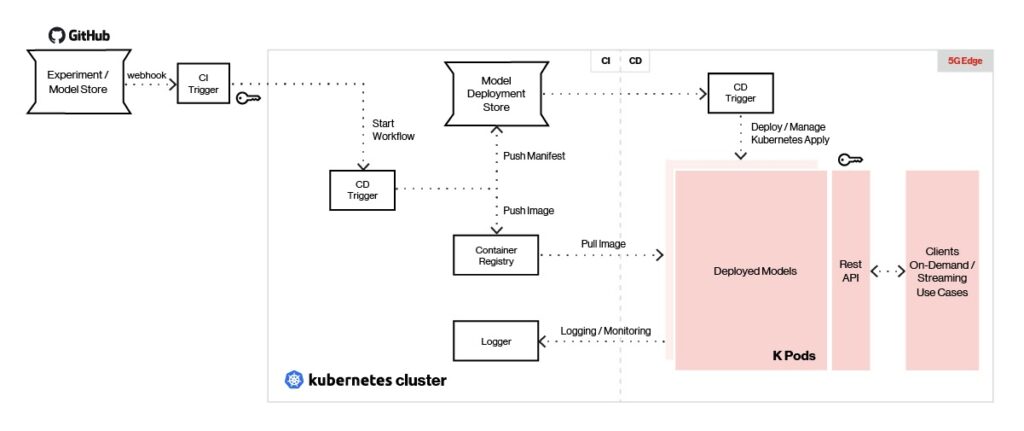
Figura 5. L’intelligenza artificiale perimetrale può servire modelli creati con qualsiasi tipo di framework di apprendimento automatico.
Gli strumenti di integrazione continua della nostra piattaforma, come Jenkins X, consentono di trasferire i modelli al negozio di modelli all’edge della rete utilizzando trigger di distribuzione. Uno strumento di distribuzione continua come Argo CD viene utilizzato per estrarre l’immagine del modello dal repository e distribuire ciascun modello come pod autonomo.
I modelli implementati vengono serviti utilizzando Seldon con un’interfaccia REST/gRPC e il carico bilanciato dietro un gateway API. I client inviano chiamate REST/gRPC al gateway API per generare previsioni. La gestione dei modelli e le metriche vengono fornite utilizzando Seldon, mentre la registrazione e il monitoraggio vengono eseguiti utilizzando ELK Stack e/o Prometheus.
L’integrazione di intelligenza artificiale e capacità di elaborazione, insieme ai servizi cloud direttamente alla periferia della rete, consente alle organizzazioni di introdurre sul mercato casi di utilizzo aziendali in tempo reale sempre più sofisticati e trasformativi. Come descritto in questo post, la piattaforma Edge ai aiuta a rendere operativa l’intelligenza artificiale aziendale in tempo reale su vasta scala e riduce significativamente gli ostacoli legati all’introduzione di un’ampia gamma di applicazioni ML in tempo reale. Ciò consente ai clienti di accelerare l’implementazione dei progetti pilota e di scalare in modo efficace dai progetti pilota alla produzione.
Nella prossima puntata finale di questa serie di blog in tre parti, esploreremo il processo di progettazione e implementazione di soluzioni basate sulla piattaforma Edge ai e forniremo ai clienti esempi di soluzioni Edge ai per l’analisi predittiva, la produzione intelligente e la logistica.
Contact per saperne di più su come la vostra applicazione potrebbe trarre vantaggio dalla nostra piattaforma di intelligenza artificiale Edge.
Per leggere il primo blog di questa serie, fare clic qui.





