
Pubblicato originariamente il 29 settembre 2023 | aggiornato il 10 ottobre 2023
Di: Dave Andrews, Marcus Hildum, Sergio Ruiz
Aggiornamento: Attacco di ripristino rapido HTTP/2 – CVE-2023-44487
In seguito al breve blog iniziale riportato di seguito, Edgio si è impegnato con colleghi di tutto il settore sulla definizione e la divulgazione responsabile dell’ attacco CVE-2023-44487– HTTP/2 Rapid Reset.
Il problema di fondo interessa molte implementazioni di server HTTP/2, il che rende le implicazioni dell’attacco molto più ampie di quanto Edgio avesse realizzato in precedenza. Edgio consiglia a tutti i clienti che eseguono un’infrastruttura pubblica di eseguire l’aggiornamento alle versioni con patch dei propri server non appena diventano disponibili e/o disattivare temporaneamente HTTP/2.
Edgio è inoltre disponibile per contribuire a mitigare il rischio per i nostri clienti eseguendo la terminazione HTTP/2 e proxando HTTP/1,1 all’infrastruttura dei clienti. Contattateci per avviare questo processo.
Il 28 agosto 2023 alle 18:43, gli ingegneri PST di Edgio hanno osservato un aumento dell’utilizzo della memoria sui nostri edge server, dei tassi di richiesta a diverse proprietà web di grandi dimensioni e del volume di log generati all’edge.
Il traffico, presto identificato come un attacco, era nuovo perché era osservabile solo nei registri del nostro bilanciamento del carico di livello 7. “Edgio esegue il nostro motore di caching e proxy HTTP personalizzato, Sailfish, sia come bilanciamento del carico di livello 7 (che chiamiamo “frontend”) che come livello di caching e proxy (il “backend”).” Ciò consente la strumentazione comune e la registrazione a entrambi i livelli, rendendo i confronti tra di essi banali.
Quando abbiamo scavato nei registri del frontend, abbiamo osservato alcuni comportamenti interessanti che indicano un attacco:
- Il numero di richieste per i singoli client era molto più alto del solito: Durante l’attacco abbiamo visto istanze di oltre 20.000 richieste su un singolo socket.
- Nessun byte inviato ai client.
- Il tempo totale di richiesta, dall’inizio alla fine, è stato compreso tra 1 e 2 millisecondi, il tutto impiegato per avviare una nuova connessione proxy ai backend.
- Tutte le connessioni che mostravano il comportamento erano connessioni HTTP/2.
Sulla base di queste osservazioni iniziali, abbiamo teorizzato che l’utente malintenzionato stesse abbandonando le richieste utilizzando il frame RST_STREAM DI HTTP/2 e avviando nuove richieste sullo stesso socket, molto rapidamente.
Successivamente, abbiamo suddiviso i nostri sforzi in tre flussi di lavoro distinti:
- Indagando su eventuali problemi che potrebbero influire sulla libreria HTTP/2 utilizzata, nghttp2, che potrebbero dimostrare la causa principale.
- Creazione di variabili Sailfish per esporre i fondamenti di questo comportamento e abilitare le mitigazioni.
- Creazione di nuove metriche, dashboard e avvisi per identificare più rapidamente questo tipo di attacco.
1. Inviato… ma in realtà nghttp2
Dopo una piccola ricerca, abbiamo trovato in questo numero Envoy, un proxy di servizio che Edgio non utilizza sull’edge, e il corrispondente CVE. Dopo una più approfondita revisione del diff, ci siamo resi conto che questo problema non era solo in inviato, ma in realtà in nghttp2, che usiamo.
Una richiesta di pull e una release di tag point per nghttp2 sono stati rilasciati poco dopo la divulgazione, risolvendo il problema sottostante. La mancanza di un CVE specifico allocato a nghttp2 ha fatto sì che il nostro sistema di scansione CVE automatizzato, utilizzato per tenere traccia delle vulnerabilità nei software chiave utilizzati, non si sia verificato il problema.
Abbiamo avviato immediatamente il processo di aggiornamento e distribuzione di questa dipendenza, completato alcune settimane fa.
2. Percentuale di ripristino richiesta
Parallelamente, abbiamo lavorato per identificare il comportamento degli attacchi a livello di programmazione, all’interno di Sailfish stesso, al fine di poter intervenire immediatamente per evitare problemi di prestazioni o affidabilità. Abbiamo deciso di implementare una variabile di configurazione (h2_Remote_reset_percent) all’interno di Sailfish, in grado di monitorare la percentuale di richieste su una determinata connessione che è stata reimpostata dal client.
L’aggiunta, insieme a una variabile esistente per il conteggio delle richieste su una singola connessione, ci ha consentito di creare una regola che chiudesse immediatamente una connessione a un client che aveva superato una soglia di richiesta e che aveva reimpostato più di una percentuale configurata di richieste. Abbiamo inserito questa configurazione in normali casseforti operative, che ci permettono di disattivarla per specifiche posizioni o clienti.
Nello pseudocodice si presenta come:
if request_count > 1000 and
h2_remote_reset_percent > 99 and
pop ~ ".*" and
customer_id not in () then
connection.silent_close();
fi
Dopo un’attenta convalida per evitare qualsiasi impatto involontario sul traffico dei nostri clienti, è stata implementata la nuova regola e gli ingegneri Edgio hanno continuato a monitorare eventuali ulteriori anomalie.
3. Conteggi e rapporti
Per identificare più rapidamente quando si verificano attacchi di questo tipo, abbiamo configurato un nuovo dashboard e un nuovo avviso in base al numero di frame HTTP/2 RST_STREAM ricevuti dai client, in una posizione. Questo, Unito a una visione singolare della disponibilità della memoria e dei controlli di integrità, ci ha dato un chiaro segnale di potenziale degradazione dovuta a questo specifico tipo di attacco:
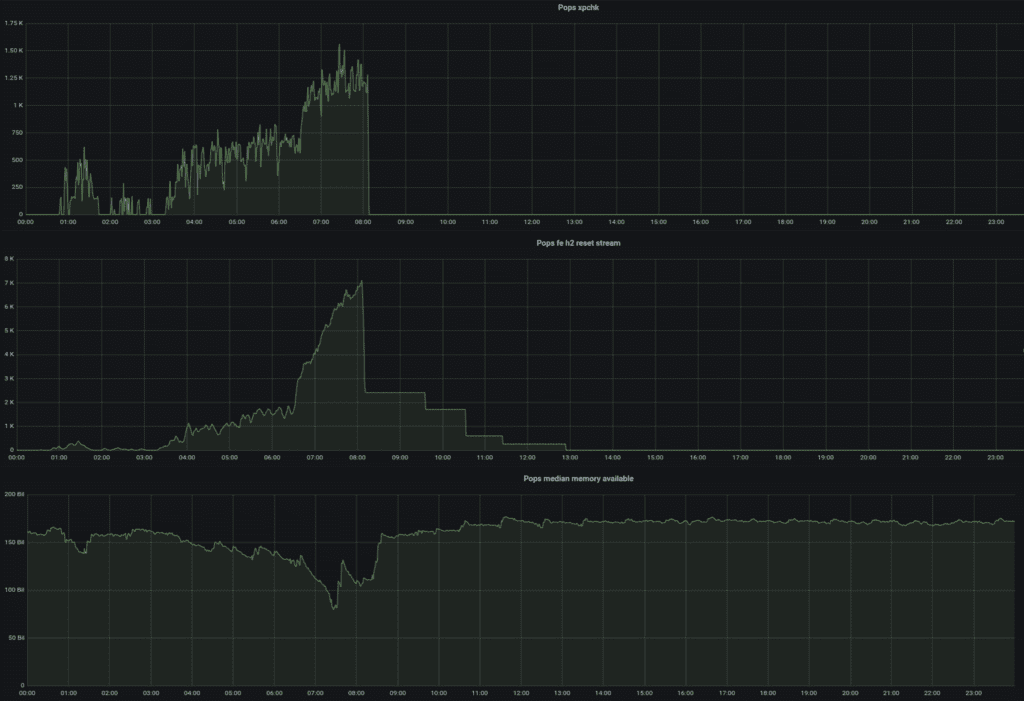
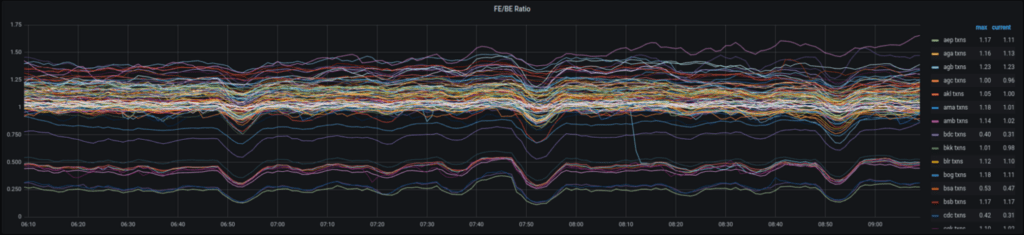
Tuttavia, siamo rimasti preoccupati per altri potenziali tipi di attacco che potrebbero influenzare solo i frontend in modo specifico. Per fornire visibilità su questa preoccupazione più generale, abbiamo iniziato a monitorare il rapporto del tasso di transazione tra front-end e back-end in una data posizione. I dati sottostanti a questo confronto sono stati una parte fondamentale del nostro monitoraggio per molto tempo.
Osservando il comportamento normale, è possibile vedere le bande forti intorno a 1, il rapporto previsto, poiché ogni richiesta che arriva a un front-end si traduce in una singola richiesta di back-end. È inoltre visibile un’area di banda più vicina a 0,5 e 0,25, che si verificano principalmente in posizioni di test inattive, dove sistemi come Purge e Health-check causano l’elaborazione di più transazioni interne da parte dei backend:
Durante l’attacco iniziale, tuttavia, è possibile vedere chiaramente l’effetto su questo rapporto:
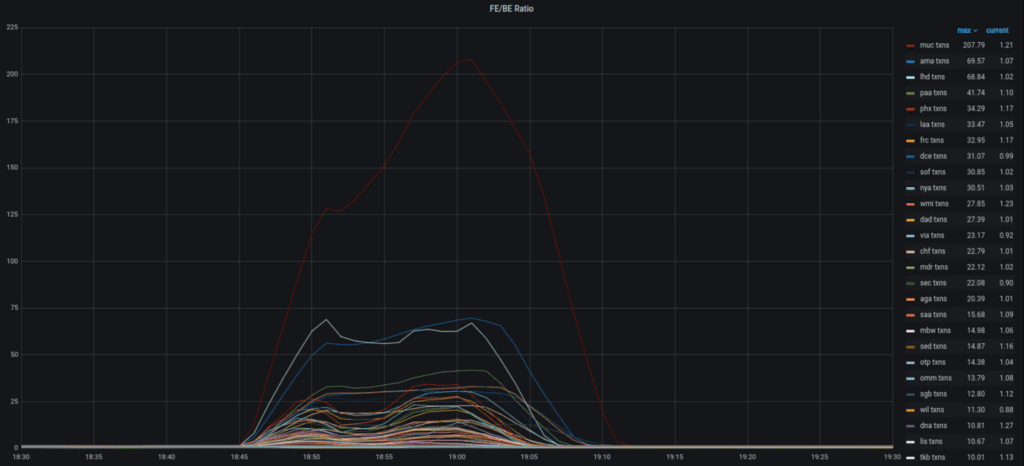
I nostri avvisi correnti sono configurati per attivarsi quando il rapporto supera un determinato valore, creando un incidente per i tecnici del supporto Edgio che possono testare e avviare le fasi di mitigazione.
Riepilogo
Si trattava di un nuovo tipo di attacco interessante, che sfruttava una vulnerabilità divulgata relativamente di recente in una libreria ampiamente utilizzata. Fortunatamente, il team di Edgio ha lavorato rapidamente per migliorare la nostra consapevolezza operativa, mitigare la causa principale specifica dell’attacco, oltre a mettere in atto mitigazioni generiche e personalizzabili per questa classe di attacchi.
Naturalmente, stiamo sempre lavorando a miglioramenti come questo, come nuovi modi per identificare i malintenzionati tramite impronte digitali, oltre a integrare questo lavoro nella nostra suite di prodotti per la sicurezza per consentire un blocco e una limitazione della velocità più persistenti.
Mai un momento noioso a Edgio.
Per ulteriori informazioni sulla nostra protezione DDoS a spettro completo, parte della premiata soluzione WAAP (Web Application and API Protection) di Edgio, contattate i nostri esperti qui.





