

Arrière-plan
Les CDN et les fournisseurs de cloud fournissent de grands volumes de trafic sur Internet et utilisent des outils de surveillance étendus pour assurer les performances et la fiabilité. Il s’agit notamment d’outils qui couvrent diverses couches de distribution du trafic telles que réseau, serveur, application, etc TCP/IP représente la majorité de ce trafic (alors que le protocole QUIC UDP est en augmentation à l’échelle mondiale, il ne représente qu’une petite fraction du trafic total par rapport au protocole TCP).
Les sockets sont des abstractions de système d’exploitation qui relient la connexion client et serveur sur laquelle les données sont transmises. Les problèmes de réseau sont donc directement reflétés dans les données stockées avec chaque socket. Par exemple, l’encombrement du réseau peut entraîner des temps de réponse lents et une augmentation des temps d’aller-retour (RTT). Il est également possible que la bande passante du réseau soit disponible, mais l’application est submergée par trop de requêtes et ne peut pas remplir le tampon avec suffisamment de données pour utiliser pleinement la bande passante disponible, ce qui entraîne une anomalie limitée à l’application. Souvent, les serveurs gèrent plusieurs sockets en même temps, ce qui peut conduire à des conflits de ressources mettant à rude épreuve les ressources système telles que le processeur et la mémoire.
Ainsi, la surveillance des performances des sockets TCP à grande échelle peut fournir une compréhension critique des comportements du trafic, tels que les temps de réponse lents ou les connexions perdues, et identifier les cas où des améliorations peuvent être apportées.
Outils existants
L’utilitaire « ss » sous Linux est un outil courant utilisé pour obtenir des statistiques de socket. Similaire à « netstat », ss fournit un mécanisme plus rapide et plus flexible pour obtenir des informations en autorisant des filtres sur les états des sockets, les protocoles et les adresses. Nous avons également commencé notre parcours de surveillance des sockets avec ss. Bien qu’il s’agisse d’un outil puissant pour obtenir rapidement une liste de sockets et des métriques pertinentes, le principal défi de ss est qu’il peut consommer des ressources importantes, en particulier lorsqu’il est utilisé sur des systèmes avec un grand nombre de sockets. Cela peut avoir un impact sur les performances du système et ralentir d’autres processus. De plus, la sortie ss n’est pas idéale pour l’analyse, en raison de l’utilisation incohérente de la clé : valeur, et complique considérablement la capacité de diffuser des données collectées à partir de milliers de serveurs.
Notre première version de la collection de sockets utilisant ss était un script bash exécuté sur des serveurs de cache sélectionnés que nous exportons la sortie de “ss –tcp –info” dans un fichier. Ce fichier serait ensuite rsync-ed à un hôte bastion à partir duquel un script python le lirait, l’analyserait et l’insérerait dans ElasticSearch. Cela a permis de faire le travail, mais n’était nulle part près de l’échelle dont nous avions besoin. La prochaine itération de ce travail a été d’avoir un script python en direct sur les serveurs de cache qui serait appelé à partir d’une interface HTTP et retournerait les statistiques agrégées pour être insérées dans le cluster ElasticSearch. Cette méthode a fait évoluer le goulot d’étranglement de l’analyse d’un emplacement central de back-office vers le serveur de cache individuel, mais a entraîné une utilisation importante de la mémoire sur les serveurs dotés d’un nombre de sockets significativement élevé. Finalement, nous avons reconnu la nécessité d’un remplacement léger pour la partie ss du système.
Nos principales exigences pour ce nouvel outil étaient qu’il soit léger et évolutif pour le grand nombre de sockets dont disposent nos serveurs CDN et qu’il soit capable de diffuser des données en arrière à l’aide d’un mécanisme efficace tel que des tampons de protocole. TCP-info outil du MeasurementLab est un excellent utilitaire implémenté dans Golang. Cependant, il est conçu pour suivre les mêmes prises au fil du temps. Étant donné le grand volume de nos connexions de prise, nous avons fait un choix de conception pour ne pas suivre les prises individuelles. Au lieu de cela, demandez à chaque boucle d’interrogation d’être indépendante, fournissant un instantané de l’état actuel des sockets ouverts. L’objectif principal ici est de suivre les performances globales du système et non les sockets individuels.
XTCP
Pour résoudre ces défis, nous introduisons et open-source xTCP (extraction, exportation, Xray TCP). XTCP est un utilitaire Golang pour capturer et diffuser des données de socket à grande échelle. XTCP utilise Netlink pour capturer les informations de socket, empaqueter les données dans des protobufs et les envoyer via un port UDP (pour être éventuellement envoyé à Kafka, etc.) ou écrire dans NSQ.
NetLink fournit une interface générique pour la communication entre l’espace utilisateur et l’espace noyau. Outils de surveillance des sockets ss, tcp-info utilisez NETLINK_INET_DIAG, qui fait partie de la famille de protocoles Netlink, pour obtenir des informations sur les sockets du noyau dans l’espace utilisateur (remarque de la page man : NETLINK_INET_DIAG a été introduit dans Linux 2.6.14 et supporté uniquement les sockets AF_INET et AF_INET6. Dans Linux 3,3, il a été renommé NETLINK_SOCK_DIAG et étendu pour supporter les sockets AF_UNIX).
XTCP extrait les données TCP INET_DIAG du noyau à des débits élevés et exporte ces données via des protobufs. Sur une machine avec environ ~120k sockets, les messages Netlink sont d’environ ~5-6 Mo, cependant, la sortie ASCII de ss est d’environ ~60Mo. De plus, ss lit à partir du noyau en fragments de ~3 Ko par défaut. XTCP lit des tronçons de 32 Ko et minimise ainsi les appels système. XTCP lit les données de socket Netlink simultanément en utilisant plusieurs workers pour vider la file d’attente aussi rapidement que possible et analyse simultanément les messages Netlink pour le streaming. Toutes ces optimisations réduisent l’encombrement de xTCP pour une exécution sur des serveurs de cache de production.
Utilisation chez Edgio
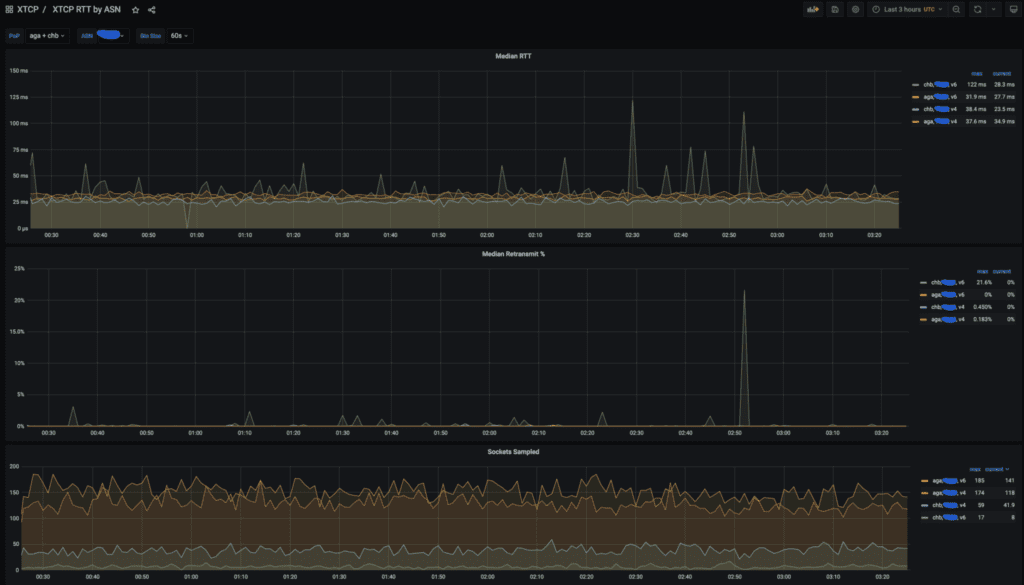
Nous utilisons fortement les données xTCP pour analyser les performances des clients. Généralement, nous suivons RTT et retransmettons agrégés par point de présence (POP) et ASN.
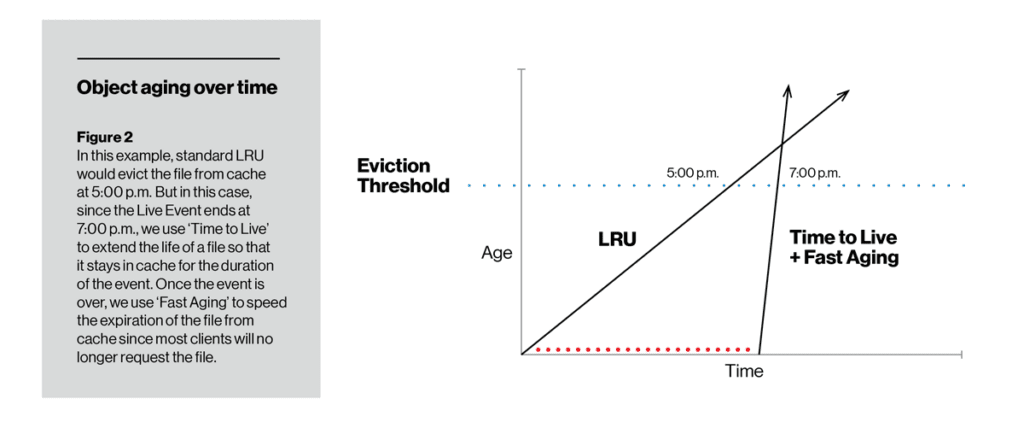
Contrairement au taux de vieillissement, TTL nous permet de modifier la capacité de cache d’un élément particulier. Pendant la durée définie à l’aide de la fonction TTL, un élément ne vieillit pas alors qu’il est sur le disque, il est donc moins probable (même très peu probable) d’être expulsé. Une fois le TTL expiré, l’élément peut commencer à vieillir soit de la manière LRU traditionnelle, soit avec un vieillissement rapide ou lent (selon la façon dont l’opérateur le configure). Dans la figure ci-dessous, TTL avec vieillissement lent a conservé un élément sur le disque au point où il ne dépassait pas le seuil d’expulsion du cache. À l’opposé, TTL s’est assuré qu’un flux vidéo en direct était mis en cache au moins pendant la durée de l’événement, mais qu’après cela a été rapidement supprimé du disque en utilisant un vieillissement rapide.
Un exemple de tableau de bord xTCP montrant RTT, les retransmissions et le nombre de sockets échantillonnés pour POPS AGA et CHB pour un grand fournisseur américain.
Dans un précédent billet de blog, nous avons présenté notre pipeline pour le réglage dynamique du contrôle de congestion pour activer automatiquement BBR pour les clients qui sont sous-performants et où nous savons que le mécanisme de BBR serait le plus utile. Les données xTCP sont la source principale de l’analyse.
Nous trouvons constamment de nouvelles façons d’utiliser les données xTCP pour répondre à des questions complexes telles que l’impact de la congestion, et le machine learning pour prédire les performances et détecter les anomalies. Nous prévoyons de rendre compte de cette analyse des données de socket dans un prochain article de blog.
Aujourd’hui, xTCP rejoint vFlow (sflow, netflow, ipfix collector) dans notre suite d’outils open source de surveillance réseau. Nous espérons que cela servira la communauté de surveillance de la performance de l’infrastructure pour la collecte de données socket et nous attendons avec impatience une participation active à la poursuite de cet outil.
Accusé de réception
Le succès et la grande convivialité de xTCP sont le résultat des contributions d’individus et d’équipes à travers Edgio. Nous tenons à remercier tout particulièrement David Seddon qui est le développeur initial de xTCP. Un merci spécial à tous les réviseurs de code internes et contributeurs pour les tests, l’ingesting, les tableaux de bord et les commentaires sur xTCP.





