

Les applications d’IA d’entreprise en temps réel dans divers secteurs industriels nécessitent une plate-forme de données exploitables en temps réel et de ML Insights avec une interconnexion agnostique dans le cloud. Edge ai de Verizon Media est une plate-forme spécialement conçue pour aider les clients au croisement de la gestion des données et des opérations d’apprentissage automatique (MLOps), afin qu’ils puissent fonctionner sur une infrastructure hétérogène à l’échelle mondiale. Le déplacement de l’intelligence artificielle à la périphérie du réseau permet de prendre des décisions et des actions en temps quasi réel. Cela ouvre une gamme d’applications passionnantes et transformatrices dans les segments industriels et grand public, que nous avons décrites dans le premier article de cette série.
À bien des égards, comme nous l’expliquerons, l’objectif de Edge ai est de connecter tous les éléments nécessaires pour concevoir, développer et déployer des applications commerciales d’IA à la périphérie pour permettre des cas d’utilisation en entreprise en temps réel. Cela inclut notre réseau de diffusion de contenu (CDN), avec seulement 10-25 millisecondes de latence pour pratiquement tous les internautes du monde entier, notre technologie 5G sur site, une plate-forme d’application extensible en tant que couche de service (aPaaS), la gestion des données cloud, une sécurité complète et une surveillance et des analyses approfondies.
Dès le début du processus de développement de l’IA Edge, notre vision était de créer une plate-forme conteneurisée légère indépendante de l’infrastructure avec une interconnexion indépendante du cloud pour fournir des données exploitables en temps réel et des informations d’apprentissage automatique à la périphérie. Cette vision, à son tour, nous a aidés à respecter les objectifs et les décisions technologiques de la plateforme, comme indiqué dans la figure ci-dessous.
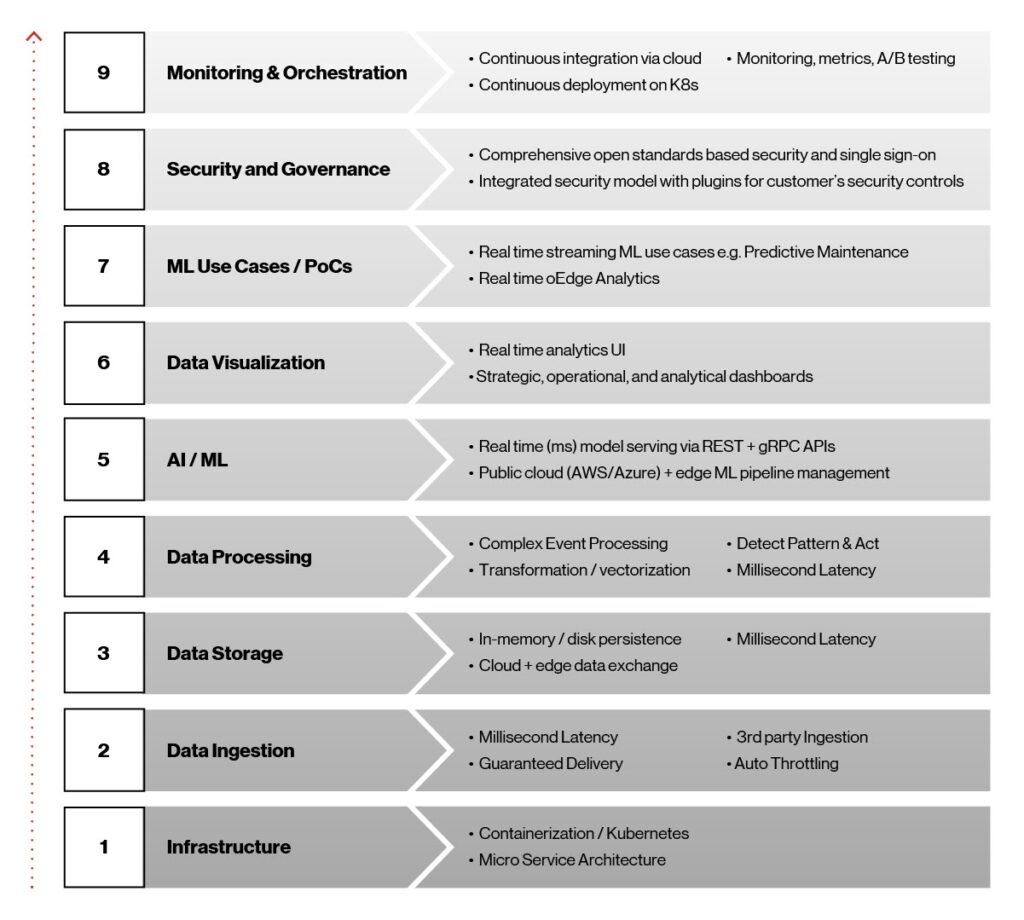
Figure 1. Eléments architecturaux Edge ai.
Ces neuf éléments jouent un rôle essentiel dans la réalisation de la plateforme Edge ai et sont essentiels à son succès lorsque des solutions commerciales sont déployées en production. Regardons de plus près ces éléments, en travaillant de bas en haut.
-
Infrastructure : Kubernetes et les conteneurs étaient les choix évidents pour la haute disponibilité, la latence ultra-faible et le déploiement rapide des modèles ai/ML à la périphérie. Kubernetes est une plate-forme open source portable, extensible et indépendante de l’infrastructure pour la gestion des charges de travail et des services conteneurisés. Nos conteneurs sont basés sur la plateforme Docker, un moyen efficace de packager et de livrer des logiciels, et fonctionnent sur les services Kubernetes gérés fournis par les principaux fournisseurs de cloud comme AWS, Microsoft Azure et Google.
-
Ingestion de données : pour que les modèles ai/ML évoluent et réalisent leur potentiel, les données doivent passer de l’ingestion à plusieurs systèmes en aval, tels qu’un tableau de bord pour l’analyse et la surveillance ou des fichiers basés sur Apache Hadoop pour la formation aux modèles. Pour cette fonction, nous utilisons Apache Kafka, qui offre l’ingestion de données en temps réel, l’intégration, la messagerie et pub/sub à grande échelle. La couche d’ingestion de données multipartites qui en résulte fournit une latence de l’ordre de quelques millisecondes, une livraison garantie et une prise en charge de la limitation.
-
Stockage de données à latence Low : le stockage de données joue un rôle important dans l’IA Edge en raison de son besoin de latence inférieure à la seconde, d’un débit élevé et d’une couche de stockage de données à faible encombrement, ainsi que de la possibilité de se synchroniser avec diverses plates-formes cloud pour le stockage et les informations historiques. Ici, nous nous sommes tournés vers le système de base de données Redis NoSQL. Les bases de données NoSQL, telles que Redis, sont moins structurées que les bases de données relationnelles. De plus, ils sont plus flexibles et peuvent évoluer plus facilement, ce qui en fait la solution idéale pour cette application.
-
Data traitement : le traitement des flux en temps réel est nécessaire dans Edge ai pour capturer des événements provenant de diverses sources, détecter des conditions complexes et publier sur divers terminaux en temps réel. Nous utilisons le Siddhi Complex Event Processor (CEP). Il s’agit d’un système CEP open source, cloud natif, évolutif et de micro-streaming capable de créer des applications orientées événements pour des cas d’utilisation tels que l’analyse en temps réel, l’intégration de données, la gestion des notifications et la prise de décision adaptative.
-
Service AI/ML : la plate-forme Edge ai fournit un déploiement IA/ML complet et une gestion du cycle de vie sur l’infrastructure cloud et Edge en temps réel via le framework open source Seldon.io. Il prend en charge plusieurs outils et langages hétérogènes.
-
Data visualisation : les visualisations pour l’analyse en temps réel et le tableau de bord sont construites à l’aide du tableau de bord Grafana et des services REST Node.js développés sur mesure pour les requêtes en temps réel des magasins de données Redis.
-
ML formation et cas d’utilisation : la plate-forme Edge ai prend en charge les frameworks ML les plus populaires, notamment SCI-kit-Learn, TensorFlow, Keras et PyTorch, et fournit une gestion complète du cycle de vie des modèles. Une fois les modèles développés et testés, ils sont entraînés à l’aide de grands ensembles de données, empaquetés et finalement déployés en toute transparence à la périphérie.
-
sécurité et gouvernance : la sécurité est intégrée à toute la plateforme Edge ai. Il peut s’adapter à des cadres de sécurité personnalisables, est indépendant des scénarios de déploiement client et est interopérable à travers une stratégie multi-cloud.
-
Monitoring et orchestration : nous réalisons l’orchestration du cloud à la périphérie via le pipeline ci/CD à l’aide d’outils tels qu’Argo CD, un outil de livraison continue pour Kubernetes. Notre objectif était de rendre le déploiement des applications Edge ai et la gestion du cycle de vie automatisés, vérifiables et faciles à comprendre.
Platform architecture de référence
Si vous avez un aperçu des technologies en jeu dans la plateforme Edge ai, voyons comment elles Now intègrent. Comme le montre la figure ci-dessous, l’architecture de la plate-forme Edge ai comporte trois parties principales :
-
Ingestion et traitement des données
-
Formation modèle
-
Modèle de déploiement et de service
Les modèles sont formés sur le cloud et servis à la périphérie pour des cas d’utilisation en temps réel. L’inférence par lots, qui n’est pas dépendante du temps, a lieu dans le cloud.
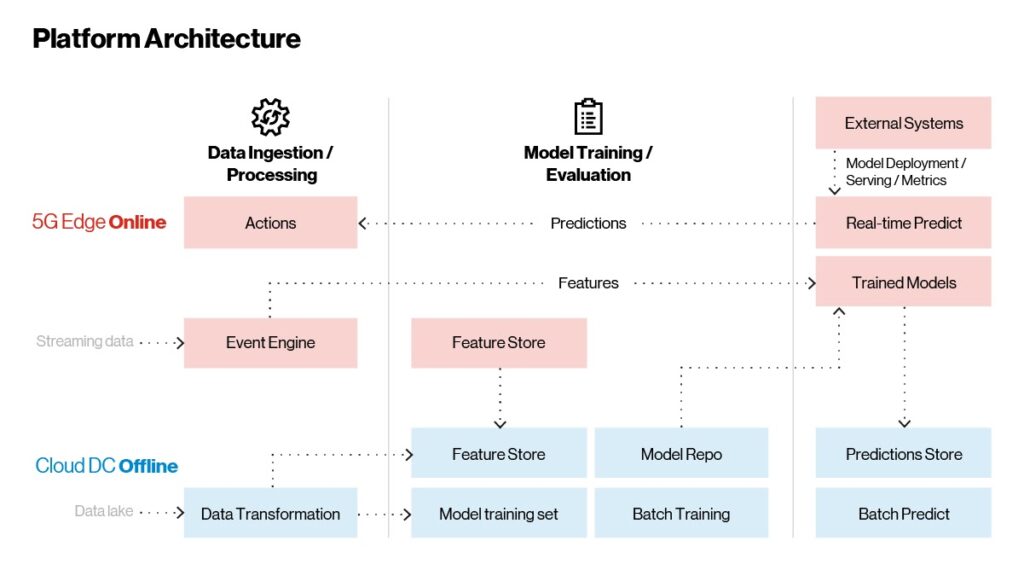
Figure 2. Edge ai : architecture de référence.
Contrairement aux applications traditionnelles, qui peuvent être implémentées, déployées et mises à jour occasionnellement, les applications ai/ML apprennent et s’améliorent constamment. La plate-forme comporte trois flux de travail principaux qui nous aident à accomplir les tâches ci-dessus :
-
Workflow de streaming en temps réel : C’est là que la fonction principale de l’application a lieu. Un CEP capture et traite les données en continu et analyse intelligemment les informations ou les conditions d’erreur. Le CEP extrait des caractéristiques ou des informations remarquables du flux brut de données entrantes et les envoie aux modèles formés pour analyse. En temps réel, les prédictions sont renvoyées au moteur de règles CEP pour agrégation. Si certaines conditions sont remplies, des mesures sont prises, telles que l’arrêt d’un système externe ou l’alerte d’un opérateur de machine en cas de défaillance potentielle. Toutes les prédictions et inférences en temps réel sont transmises au cloud hors ligne pour une surveillance et une évaluation plus poussées. C’est dans cette zone que les fonctionnalités sont mises à jour en fonction de l’évolution des données, ce qui permet aux clients de réaliser des travaux d’ingénierie intégrés au pipeline d’apprentissage automatique décrit dans la figure 4 ci-dessous.
-
Workflow à la demande avec lots de données : les systèmes externes tels que la recommandation ou la personnalisation peuvent intégrer des modèles dans la plate-forme Edge. Ceux-ci sont exposés en tant que points de terminaison REST ou GRPC via une passerelle API intégrée, permettant des appels d’inférence et des prédictions en temps réel.
-
Historical flux de travail Insights : toutes les données (brutes, agrégées et prédictions) sont stockées dans un stockage en mémoire dans la plate-forme Edge. Ces données sont synchronisées périodiquement avec les plateformes cloud via des connecteurs cloud. Une fois que les données atterrissent dans le cloud, elles sont utilisées pour reformer et faire évoluer les modèles pour une amélioration continue. Les modèles recyclés suivent un cycle de vie complet, de la formation au suivi en passant par la publication sur le cloud. Les modèles publiés sont ensuite transmis de manière transparente à la plate-forme de périphérie dans le cadre d’un déploiement continu. Les analyses historiques et l’inférence par lots sont effectuées dans le cloud.
Ingestion, traitement et stockage d’IA Edge
One L’un des aspects les plus importants d’une solution ai/ML est la capacité de capturer et de stocker des données avec rapidité et efficacité. Les volumes de données peuvent être énormes pour certaines applications, telles que les capteurs IoT. Pour vous donner une idée de l’échelle, IDC prévoit que les appareils IoT généreront à eux seuls près de 80 zettaoctets de données d’ici 2025.
Pour prendre en charge même les volumes de données les plus massifs, la plateforme Edge ai, comme indiqué ci-dessous, prend en charge plusieurs sources d’ingestion (IoT, vidéo, localisation et capteurs), protocoles et fournisseurs d’ingestion. Il prend également en charge un débit élevé avec une faible latence (millions d’événements/seconde avec une latence de 10 ms).
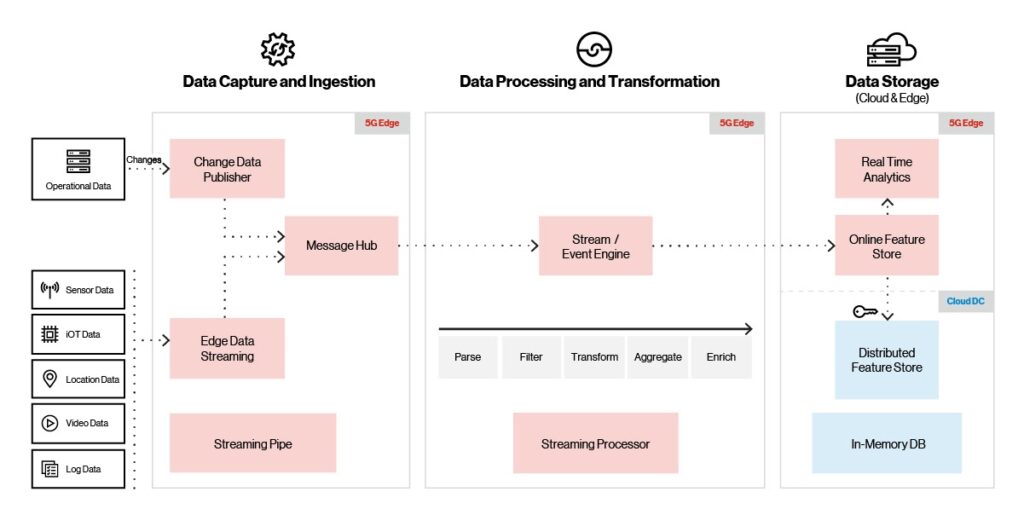
Figure 3. Ingestion, traitement et stockage de la plate-forme.
Lorsque les données vidéo, IoT ou de capteur entrantes arrivent, la couche d’ingestion utilise la limitation intégrée pour garantir la livraison des données et éviter les conditions de débordement. Un courtier de messages transmet les données entrantes au moteur de flux/événements, où elles sont transformées, enrichies ou nettoyées avant de passer à la mémoire. Une fois que les données sont dans le magasin de mémoire, elles sont périodiquement synchronisées avec le magasin de cloud distribué. Les outils de visualisation fournissent des analyses en temps réel et des tableaux de bord opérationnels utilisant les données dans le magasin de mémoire.
Machine pipeline d’apprentissage
Machine L’apprentissage repose sur des algorithmes ; à moins d’être un scientifique des données ou un expert EN ML, ces algorithmes sont très compliqués à comprendre et à travailler. C’est là qu’intervient un cadre d’apprentissage automatique, permettant de développer facilement des modèles ML sans une compréhension approfondie des algorithmes sous-jacents. Bien que TensorFlow, PyTorch et SCI-kit-learn soient sans doute les frameworks ML les plus populaires aujourd’hui, ce ne sera peut-être pas le cas à l’avenir, il est donc important de choisir le framework le mieux adapté à l’application prévue.
À cette fin, la plate-forme Edge ai prend en charge une gamme complète de frameworks ML pour la formation aux modèles, l’ingénierie des fonctionnalités et le service. Comme le montre la figure ci-dessous, Edge ai prend en charge la gestion complète du cycle de vie des modèles, y compris la formation, le suivi, le packaging et le service.
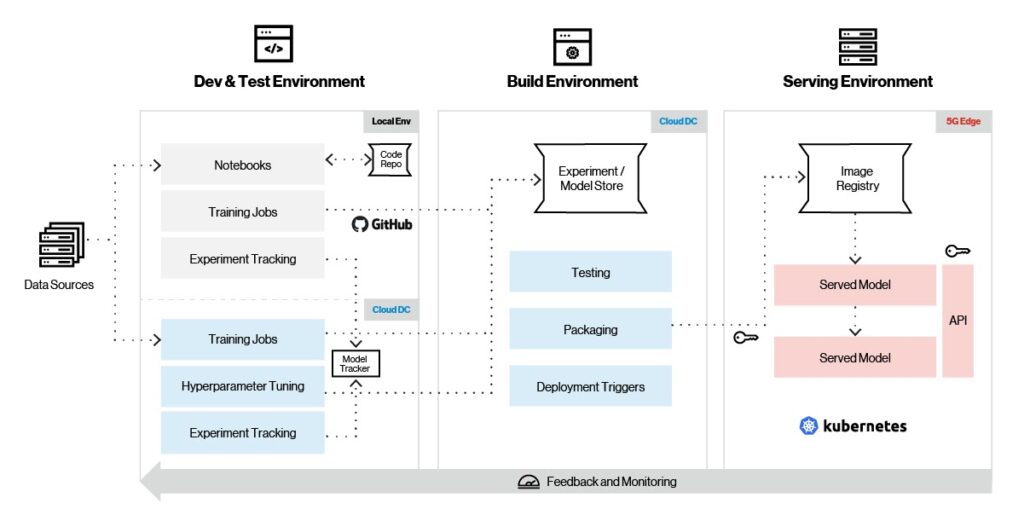
Figure 4. Pipeline d’apprentissage automatique.
Examinons le flux de travail typique de machine learning sur la plateforme Edge ai. Tout d’abord, vous exploitez le framework ML de votre choix pour créer un modèle dans un environnement local. Une fois le modèle assemblé, les tests commencent avec de petits ensembles de données et les expériences sont capturées à l’aide d’outils de cycle de vie du modèle tels que MLflow et Sagemaker. Après les tests initiaux, le modèle est prêt à être entraîné dans le cloud sur des ensembles de données plus importants, avec le réglage des hyperparamètres. Les versions des modèles sont stockées dans des référentiels de modèles sur le cloud.
Une fois que le modèle a été entièrement formé dans le cloud, l’étape suivante est le déploiement initial à la périphérie pour d’autres tests. Le modèle est ensuite soumis à des tests finaux et le packaging – et basé sur certains déclencheurs de déploiement en périphérie – est extrait du cloud et déployé de manière transparente sur la plateforme de périphérie. Les métriques du modèle sont collectées en continu et envoyées au cloud pour un réglage et une évolution ultérieurs du modèle.
Platform servir et surveiller
For flexibilité maximale dans la sélection et la prise en charge du framework ML, la plate-forme Edge ai utilise des points de terminaison REST ou GRPC pour servir les modèles en temps réel. Un aperçu de l’architecture de service et de surveillance est présenté ci-dessous.
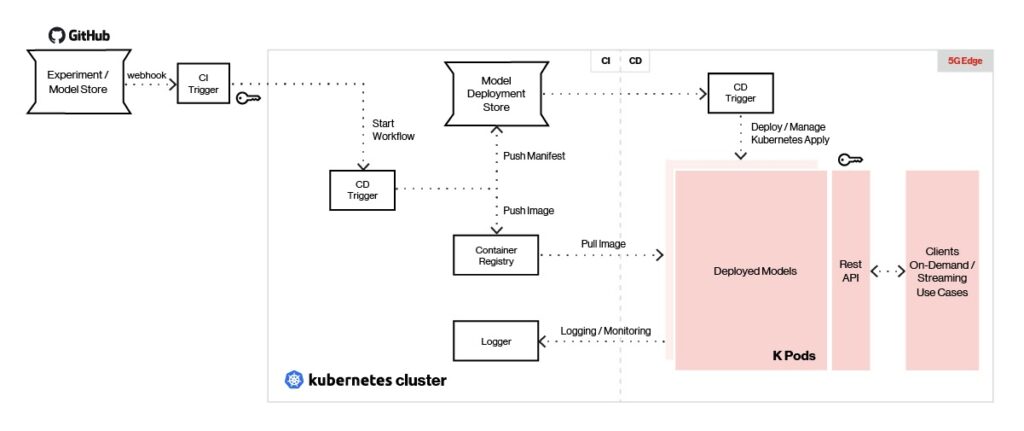
Figure 5. Edge ai peut servir des modèles créés avec n’importe quel type de structure d’apprentissage automatique.
Les outils d’intégration continue de notre plateforme tels que Jenkins X permettent de pousser les modèles vers le magasin de modèles à la périphérie à l’aide de déclencheurs de déploiement. Un outil de déploiement continu comme Argo CD est utilisé pour extraire l’image du modèle du référentiel et déployer chaque modèle en tant que pod autonome.
Les modèles déployés sont servis à l’aide de Seldon avec une interface REST/GRPC et une charge équilibrée derrière une passerelle API. Les clients envoient des appels REST/GRPC à la passerelle API pour générer des prédictions. La gestion des modèles et les mesures sont fournies à l’aide de Seldon, et la journalisation et la surveillance sont effectuées à l’aide de ELK Stack et/ou Prometheus.
L’intégration de l’IA et de la capacité de calcul, combinée à des services cloud directement à la périphérie du réseau, permet aux entreprises de commercialiser des cas d’utilisation en temps réel de plus en plus sophistiqués et transformateurs. Comme décrit dans cet article, la plate-forme Edge ai aide à opérationnaliser l’IA d’entreprise en temps réel à grande échelle et réduit considérablement les obstacles à la mise en œuvre d’un large éventail d’applications ML en temps réel. Cela permet aux clients d’accélérer la mise en œuvre des pilotes et d’évoluer efficacement des pilotes à la production.
Dans le prochain volet final de cette série de blogs en trois parties, nous explorerons le processus de conception et de déploiement de solutions basées sur la plateforme Edge ai et fournirons des exemples de solutions Edge ai pour les clients dans les domaines de l’analyse prédictive, de la fabrication intelligente et de la logistique.
Contact nous pour en savoir plus sur la façon dont votre application pourrait bénéficier de notre plateforme Edge ai.
Pour lire le premier blog de cette série, cliquez ici.





