

Real-time enterprise AI applications in various industrial sectors require a real-time actionable data and ML insights platform with cloud-agnostic interconnect. Verizon Media’s Edge AI is a purpose-built platform focused on helping customers at the intersection of data management and machine learning operations (MLOps), so they can operate on a heterogeneous infrastructure at a global scale. Moving artificial intelligence to the network edge enables decisions and actions to be taken in near real-time. This opens up a range of exciting and transformative applications in industrial and consumer segments, which we outlined in the first blog post in this series.
In many ways, as we will explain, the purpose of Edge AI is to connect all the elements needed to design, develop and deploy commercial AI applications on the edge to enable real-time enterprise use cases. This includes our content delivery network (CDN), with just 10-25 milliseconds of latency for virtually every internet user worldwide, our on-premises 5G technology, an extensible application platform as a service (aPaaS) layer, cloud data management, comprehensive security and in-depth monitoring and analytics.
From the outset of the Edge AI development process, our vision was to create an infrastructure-agnostic lightweight containerized platform with cloud-agnostic interconnect to deliver real-time, actionable data and machine-learning insights on the edge. This vision, in turn, helped us adhere to goals and technology decisions for the platform, as outlined in the figure below.
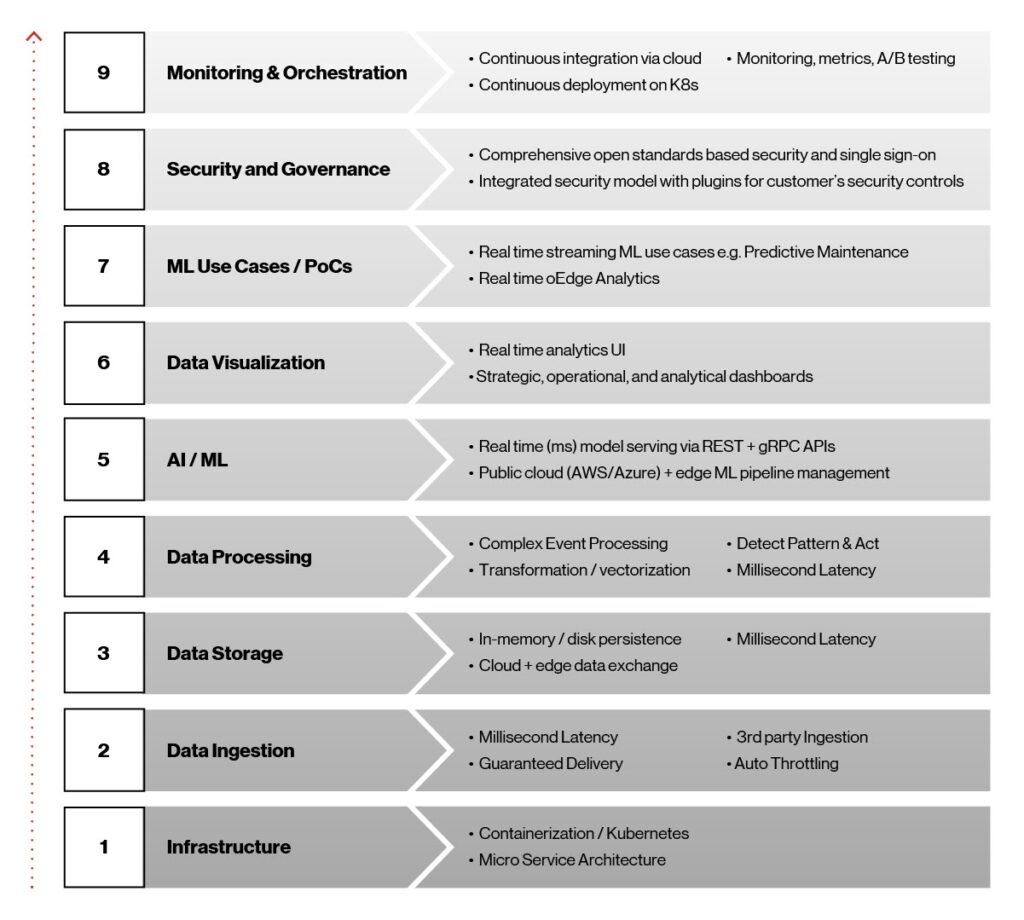
Figure 1. Edge AI architectural elements.
These nine elements play an essential role in making the Edge AI platform possible and are critical to its success as commercial solutions are deployed into production. Let’s take a closer look at these elements, working from the bottom up.
Infrastructure: Kubernetes and containers were the obvious choices for high availability, ultra-low latency and fast deployment of AI/ML models to the edge. Infrastructure-agnostic Kubernetes is a portable, extensible, open-source platform for managing containerized workloads and services. Our containers are based on the Docker platform, an efficient way to package and deliver software, and work on managed Kubernetes services provided by leading cloud providers like AWS, Microsoft Azure and Google.
Data ingestion: For AI/ML models to evolve and achieve their potential, data must flow from ingest to multiple downstream systems, such as a dashboard for analytics and monitoring or Apache Hadoop-based files for model training. For this function, we’re using Apache Kafka, which offers real-time data ingestion, integration, messaging and pub/sub at scale. The resulting multi-party data ingestion layer provides millisecond latency, guaranteed delivery and support for throttling.
Low-latency data storage: Data storage plays an important role in Edge AI due to its need for sub-second latency, high throughput, and a low-footprint data storage layer, along with the ability to sync back to various cloud platforms for storage and historical insights. Here, we turned to the Redis NoSQL database system. NoSQL databases, such as Redis are less structured than relational databases. Plus, they are more flexible and can scale better—making them the ideal solution for this application.
Data processing: Real-time stream processing is required in Edge AI to capture events from diverse sources, detect complex conditions and publish to diverse endpoints in real time. We’re using the Siddhi Complex Event Processor (CEP). It is an open-source, cloud-native, scalable, micro-streaming CEP system capable of building event-driven applications for use cases such as real-time analytics, data integration, notification management and adaptive decision-making.
AI/ML serving: The Edge AI platform provides complete AI/ML deployment and lifecycle management across the cloud and edge infrastructure in real time through the Seldon.io open-source framework. It supports multiple heterogeneous toolkits and languages.
Data visualization: Visualizations for real-time analytics and dashboarding are built using the Grafana dashboard and custom-developed Node.js REST services for real-time queries of Redis data stores.
ML training and use cases: The Edge AI platform supports the most popular ML frameworks, including sci-kit-learn, TensorFlow, Keras, and PyTorch and provides complete model lifecycle management. Once models are developed and tested, they are trained using large data sets, packaged, and ultimately deployed seamlessly on the edge.
Security and governance: Security is built-in across the entire Edge AI platform. It can accommodate customizable security frameworks and is agnostic to customer deployment scenarios and is interoperable across a multi-cloud strategy.
Monitoring and orchestration: We achieve orchestration from the cloud to the edge via the CI/CD pipeline using tools such as Argo CD, a continuous delivery tool for Kubernetes. Our objective was to make Edge AI application deployment and lifecycle management automated, auditable and easy to understand.
Platform reference architecture
Now that you have an overview of the technologies at play in the Edge AI platform, let’s look at how they fit together. As shown in the figure below, the Edge AI platform architecture has three major parts:
Data ingestion and processing
Model training
Model deployment and serving
Models are trained on the cloud and served on the edge for real-time use cases. Batch inferencing, which is not time-dependent, takes place in the cloud.
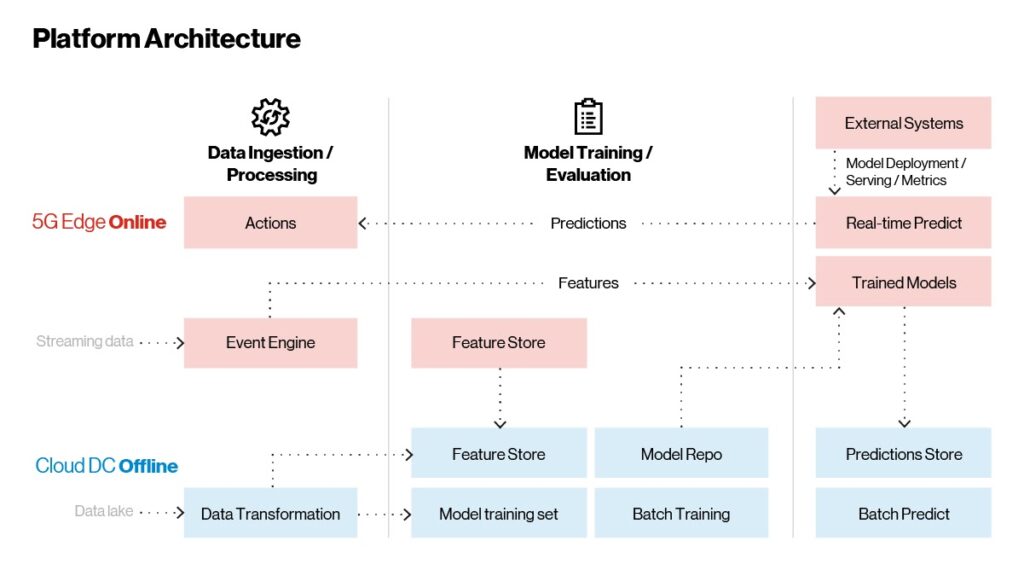
Figure 2. Edge AI—Reference architecture.
Unlike traditional applications, which can be implemented, deployed, and occasionally updated, AI/ML applications constantly learn and improve. There are three main workflows within the platform that helps us accomplish the above:
Real-time streaming workflow: This is where the application’s main function takes place. A CEP captures and processes streaming data and intelligently scans for insights or error conditions. The CEP extracts features or noteworthy information from the raw stream of incoming data and sends it to the trained models for analysis. In real time, predictions are sent back to the CEP rules engine for aggregation. If certain conditions are met, actions are taken, such as shutting down an external system or alerting a machine operator of a potential failure. All the real-time predictions and inferences are passed to the offline cloud for further monitoring and evaluation. This area is where features are updated based on evolving data enabling customers to do feature engineering integrated with the machine learning pipeline described in Figure 4 below.
On-demand workflow with batches of data: External systems such as recommendation or personalization can embed models within the edge platform. These are exposed as REST or gRPC endpoints via an embedded API gateway, allowing real-time inference calls and predictions.
Historical insights workflow: All data (raw, aggregated and predictions) is stored within an in-memory store in the edge platform. This data is synchronized periodically to cloud platforms via cloud connectors. Once the data lands in the cloud, it’s used to retrain and evolve models for continuous improvement. Retrained models follow a complete lifecycle from training to tracking to publishing on the cloud. Published models are then seamlessly served to the edge platform in continuous deployment. Historical insights and batch inferencing are done in the cloud.
Edge AI ingestion, processing and storage
One of the most important aspects of an AI/ML solution is the ability to capture and store data with speed and efficiency. Data volumes can be massive for some applications, such as IoT sensors. To give you some idea of the scale, IDC predicts that IoT devices alone will generate nearly 80 zettabytes of data by 2025.
To support even the most massive data volumes, the Edge AI platform, as shown below, supports multiple ingestion sources (IoT, video, location and sensors), protocols and ingestion providers. It also supports high throughput with low latency (millions of events/second with 10ms latency).
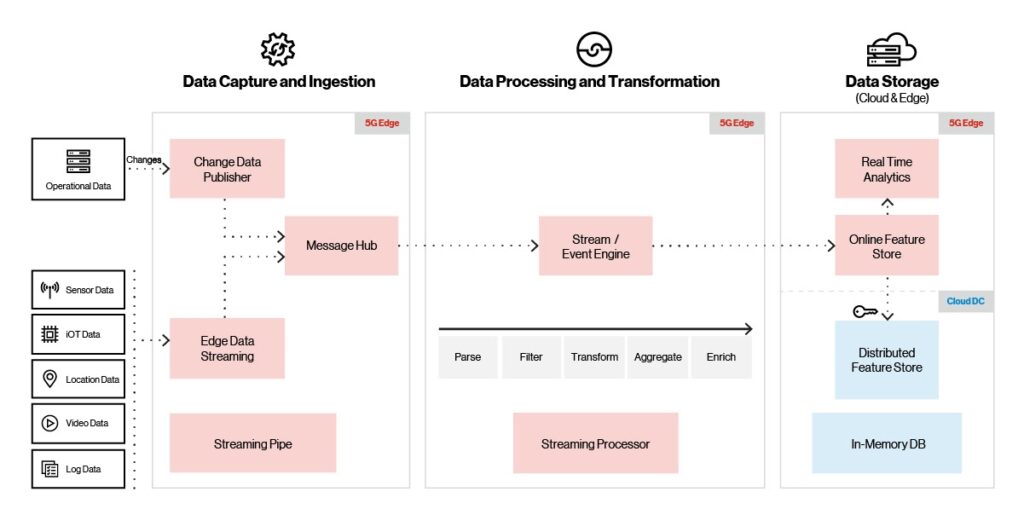
Figure 3. Platform ingestion, processing and storage.
As incoming video, IoT, or sensor data arrives, the ingestion layer uses built-in throttling to guarantee data delivery and prevent overflow conditions. A message broker delivers the incoming data to the stream/event engine, where it’s transformed, enriched, or cleansed before moving to the memory store. Once the data is in the memory store, it’s periodically synced with the distributed cloud store. Visualization tools provide real-time analytics and operational dashboards using data in the memory store.
Machine learning pipeline
Machine learning relies on algorithms; unless you’re a data scientist or ML expert, these algorithms are very complicated to understand and work. That’s where a machine learning framework comes in, making it possible to easily develop ML models without a deep understanding of the underlying algorithms. While TensorFlow, PyTorch, and sci-kit-learn are arguably the most popular ML frameworks today, that may not be the case in the future, so it’s important to choose the best framework for the intended application.
To this end, the Edge AI platform supports a full range of ML frameworks for model training, feature engineering and serving. As shown in the figure below, Edge AI supports complete model lifecycle management, including training, tracking, packaging and serving.
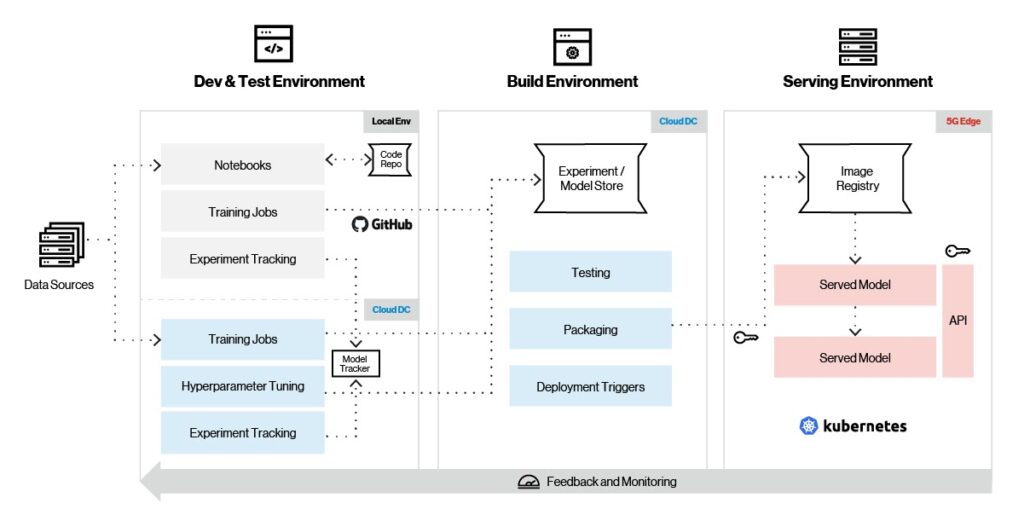
Figure 4. Machine learning pipeline.
Let’s look at the typical machine learning workflow on the Edge AI platform. First, you leverage the ML framework of choice to create a model in a local environment. Once the model is pulled together, testing begins with small data sets, and experiments are captured using model life cycle tools like MLflow and Sagemaker. After initial testing, the model is ready to be trained in the cloud on larger data sets, along with hyperparameter tuning. Model versions are stored in model repositories on the cloud.
Once the model has been fully trained in the cloud, the next step is initial deployment on the edge for further testing. The model then undergoes final testing and packaging––and based on certain deployment triggers on the edge––is pulled from the cloud and deployed seamlessly on the edge platform. Model metrics are gathered continuously and sent to the cloud for further model tuning and evolution.
Platform serving and monitoring
For maximum flexibility in ML framework selection and support, the Edge AI platform uses REST or gRPC endpoints to serve models in real time. An overview of the serving and monitoring architecture is shown below.
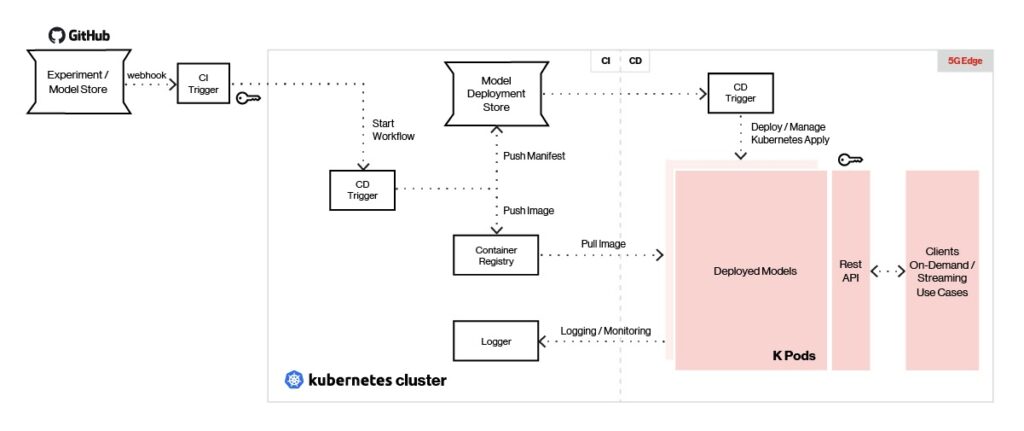
Figure 5. Edge AI can serve models created with any type of machine learning framework.
Our platform’s continuous integration tools like Jenkins X enable models to be pushed to the model store at the edge using deployment triggers. A continuous deployment tool like Argo CD is used to pull the model image from the repository and deploy each model as a self-contained pod.
Deployed models are served using Seldon with a REST/gRPC interface and load balanced behind an API gateway. Clients send REST/gRPC calls to the API gateway to generate predictions. Model management and metrics are provided using Seldon, and logging and monitoring are done using ELK Stack and/or Prometheus.
Integrating AI and compute capacity, combined with cloud services directly at the network’s edge, enables organizations to bring increasingly sophisticated and transformative real-time enterprise use cases to market. As described in this post, the Edge AI platform helps operationalize real-time enterprise AI at scale and significantly reduces the hurdles of bringing a wide range of real-time ML applications to life. This enables customers to accelerate the implementation of pilots and scale effectively from pilots to production.
In the upcoming final installment of this three-part blog series, we will explore the process of designing and deploying solutions based on the Edge AI platform and provide customer examples of Edge AI solutions in predictive analytics, smart manufacturing, and logistics.
Contact us to learn more about how your application could benefit from our Edge AI platform.
To read the first blog in this series, click here.





